 Data Structure 04 - Binary Tree
Data Structure 04 - Binary Tree

# 前置知识
在阅读本文档前,请确保你已经掌握树的基础知识,详见 Data Structure 知识板块中的 03 - Tree 文档。
# 基本概念
二叉树 (Binary Tree) 是一种追加了特殊限制的有根有序树。二叉树的每个节点最多只能有两个子节点,我们将其定义为左儿子和右儿子。也就是说,每个节点都有且仅有两棵子树——左子树和右子树(当然,它们都可以是空的)。
二叉树的递归定义和树类似。对于一棵非空二叉树 ,该树的递归定义为节点 和 的左右子树组成的节点集合。左右子树可以为空。
首先一定要牢记的是,二叉树是有序树,我们严格区分二叉树的左右,也就是说,下面的两组二叉树是不同的。
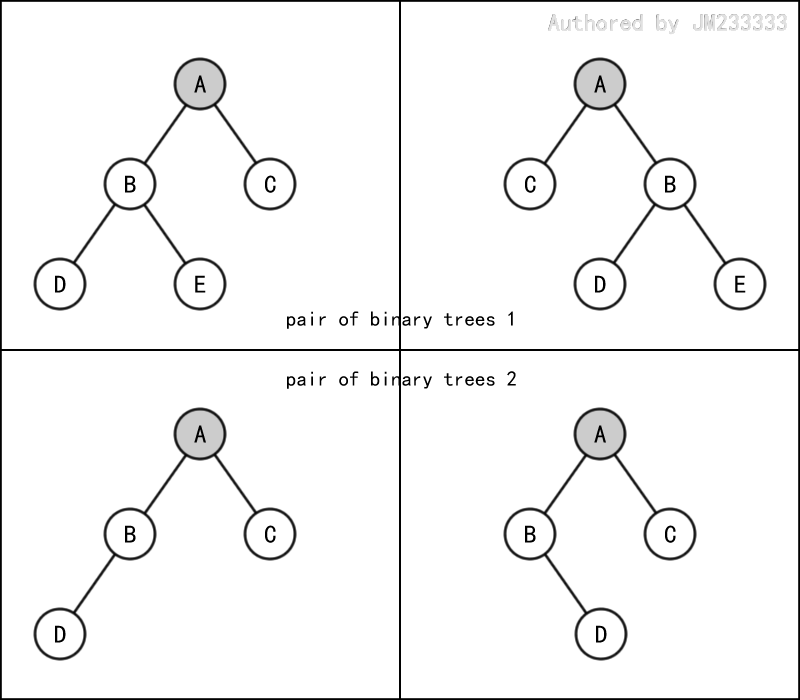
即使树上的某个节点只有一棵子树,也要区分它是该节点的左子树还是右子树。
需要注意的是,我们的教材中特别强调二叉树不能说是树的特殊形式,虽然我个人对这种咬文嚼字抠定义的事情持保留态度,但是为了考试,大家还是记住吧。
二叉树的子节点表示法又被称为二叉链表,父子节点表示法又被称为三叉链表。本文中我们均使用二叉链表。
# 概念
下面给出一些二叉树的重要性质。这些性质大多很简单,自己画一下就能想明白,因而对其证明不予赘述。
为便于描述,下文中我们均定义树的根节点的深度为 。
设 是一棵非空二叉树,则 的第 层最多有 个节点,最少有 个节点。
设 是一棵非空二叉树,设 的高度为 ,则 上最多有 个节点,最少有 个节点。
设 是一棵非空二叉树,设 有 个度数为 的节点,有 个度数为 的节点,则 。
节点个数为 的不同二叉树的种类数为 ,即卡特兰数的第 项。该性质涉及组合数学,此处不予赘述,详见其他文档。
这些定义不要去死记硬背,理解了二叉树的特点以后就可以自己随时快速地推导得到。
# 完全二叉树
完全二叉树 (Complete Binary Tree) 是一种追加了特殊限制的二叉树。设 是一棵深度为 的完全二叉树,那么除了第 层以外, 的每一层的节点个数均为最大,即第 层有 个节点。并且 的第 层上的所有节点均“尽量靠左”。
注意,这里我们定义根节点的深度为 ,下同。
如下图所示, 是完全二叉树,而 不是。
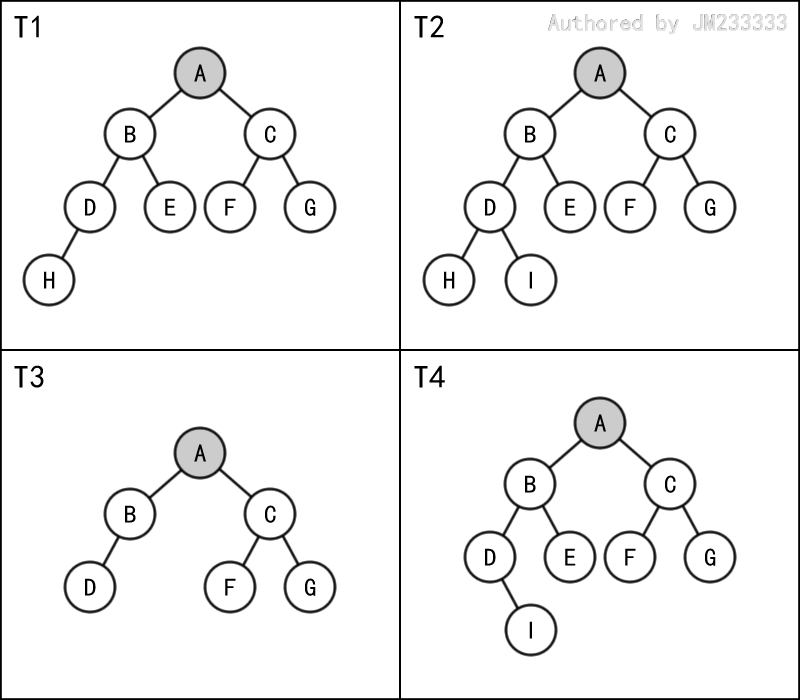
满二叉树为完全二叉树的特殊形式。设 是一棵完全二叉树,当第 层的节点个数也为最大时,称 是一棵满二叉树。
下面给出一些完全二叉树的重要性质。
设 是一棵非空完全二叉树,设 的深度为 ,则 上最多有 个节点,最少有 个节点。
设是一棵非空完全二叉树,设 的节点个数为 ,则 的深度为 。
因为完全二叉树的第 层有 个节点,若树的高度为 ,那么节点个数最多为 ,那么深度最大为 ,因此当最后一层节点个数不满时深度为 。
# 存储及表示方式
# 链式存储
二叉树的链式存储很简单,和一般树的链式存储极其相似,没有什么特别的。
// 定义
class Node {
public:
int value;
Node * left;
Node * right;
public:
Node(int v = 0) : value(v), left(nullptr), right(nullptr) {}
};
Node * root = nullptr;
# 顺序存储
对于完全二叉树,或者是已知二叉树的节点会比较密集、结构上接近于完全二叉树,我们经常还会使用顺序存储的方法,仅用一个数组来记录一棵这样的二叉树。
因为二叉树的每个节点最多只能有两个子节点,且区分左右,相比于一般树来说已经小得多,所以我们可以预先分配空间。如下图所示,我们预先规定好每个位置的节点的索引,也就是它在顺序表中的下标。
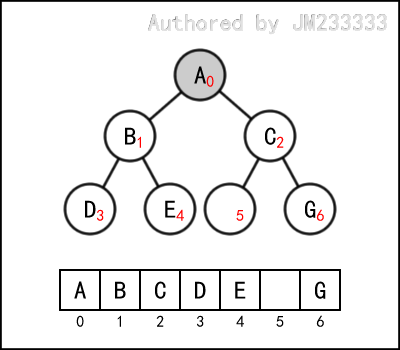
设根节点的下标为 ,那么对于树上任意节点 ,其左子节点为 ,右子节点为 ,父节点为 。
当然,如果根节点的下标为 ,那么左子节点为 ,右子节点为 ,父节点为 ,这无所谓。
数组中元素的值即为节点上的值,即节点 上的值为 。
至于如何表示对应位置处没有节点,可以在其中存储一个无效数值(例如已知数值均为非负整数则存一个 进去),或是另外开一个标记数组 来记录每个节点是否存在。
// 定义
const int MAXDEPTH = ...;
const int MAX = (1 << (MAXDEPTH + 1));
int tree[MAX];
bool existed[MAX];
不过,对于完全二叉树,我们只需记录当前的最大节点编号 即可,因为完全二叉树必须是一层一层从左往右这样存在节点,这是其性质决定的。
// 定义:完全二叉树
const int MAXDEPTH = ...;
const int MAX = (1 << (MAXDEPTH + 1));
int tree[MAX];
int trcnt = -1;
显然,在顺序存储时,我们无需再对每个节点设左右指针和父指针,仅根据当前节点的编号就能快速找到其左子节点、右子节点和父节点的编号,这意味着,当二叉树的结构密集时,使用顺序表存储法预分配空间反而比链式存储要更节约空间,尤其是完全二叉树,空间用量仅为链式存储的 或 (取决于是否需要父指针)。而且避免了指针的使用,代码实现更加简洁。此外,我们还可以在树上进行 的随机查找和修改,这是链式存储做不到的。
但是反过来说,对于节点个数少、深度大的二叉树,或者是我们无法预知二叉树的深度的上界,此时使用顺序表存储法显然是不明智的。
考虑到 和 这样的词语看起来更加直观,下面的代码示例中均采用链式存储方式。
# 二叉树的遍历
# 概念
对某种数据结构的 遍历 (traverse) ,指的是以某种顺序依次访问数据结构中存储的所有数据。对于线性结构来说,遍历是很简单的,从左往右扫一遍即可,以至于简单到我们都不需要去考虑它。但是对于非线性结构来说,遍历总是一个非常重要的话题。
二叉树的遍历是重难点知识,对于初学者来说,其逻辑过程应该是通俗易懂的,但是对于代码实现,你可能会一看就懂、但更可能会感觉非常难以理解。这没关系,初次只需大致理解即可,重点放在对其逻辑过程的掌握上。当你学习到图论,并掌握图论搜索的相关知识后,再看这些代码实现就很容易了。
因为前置知识相互交叉,所以我在此处不会写得太过详细,你可以在阅读图论中关于搜索的文档后再回来重新审视二叉树的遍历,或是交叉学习,反复交叉学习多次后,你一定可以很好地掌握这些知识。
二叉树的遍历包括 先序遍历 (pre-order traverse, or DLR) 、 中序遍历 (in-order traverse, or LDR) 、 后序遍历 (post-order traverse, or LRD) 、 层序遍历 (level-order traverse) 四种,其中前三种为一大类,均属于深度优先遍历,第四种是广度优先遍历。有时先序遍历也被称为前序遍历,二者是同义的。
所谓的先/中/后序遍历,其含义是在遍历某一棵子树时,先/中/后访问其根节点。
先序遍历:首先访问根节点,然后访问左子树,最后访问右子树,也就是 Data-Left-Right 。
中序遍历:首先访问左子树,然后访问根节点,最后访问右子树,也就是 Left-Data-Right 。
后序遍历:首先访问左子树,然后访问右子树,最后访问根节点,也就是 Left-Right-Data 。
需要注意的是,虽然根节点的访问次序不同,但左子树的访问永远在右子树的访问之前。
空口无凭,让我们结合下图中的实例来看。后续我们均以该二叉树为例。
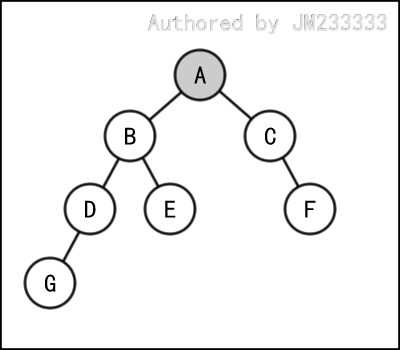
先序遍历的结果为: 。
当我们访问 时,首先访问根节点 ,然后访问左子树 ,最后访问右子树 。
当我们访问 时,首先访问根节点 ,然后访问左子树 ,最后访问右子树 。
当我们访问 时,首先访问根节点 ,然后左子树是空树,最后访问右子树 。
当我们访问 时,首先访问根节点 ,然后左子树是空树,最后右子树是空树。
中序和后序遍历也是类似的,就解释地稍微简单一些了。
中序遍历的结果为: 。
当我们访问 时,首先访问左子树 ,然后访问根节点 ,最后访问右子树 。
当我们访问 时,首先左子树是空树,然后访问根节点 ,最后访问右子树 。
后序遍历的结果为: 。
当我们访问 时,首先访问左子树 ,然后访问右子树 ,最后访问根节点 。
当我们访问 时,首先左子树是空树,然后访问右子树 ,最后访问根节点 。
所谓的层序遍历,顾名思义,就是一层一层地访问树上的节点,先后访问树的第 层,并且在每一层上都是从左到右访问。
层序遍历的结果为: 。
首先访问第 层 ,然后依次访问第 层 ,访问第 层 ,访问第 层 。
# 代码实现
下面考虑如何用代码实现二叉树的四种遍历。
你需要很好地掌握递归,或是对深度优先遍历有着一定的理解,才能真正透彻地明白先/中/后序遍历的代码实现。你需要对广度优先遍历有着一定的理解,才能真正透彻地明白层序遍历的代码实现。因此,可以先尽量尝试理解,如果理解不了没关系,初次学习不必死磕,将来再交叉学习即可。
首先,对于初学者来说,可能会完全不明白这些不同次序的遍历的意义,为什么要把它们分得这么清?不都是遍历吗,一种还不够?
我们强调过,每一种数据结构的产生都对应着实际应用中遇到的问题,将来你必定会遇到与之相关的问题。考虑到很难和初学者解释关于维护答案、维护贡献这样的东西,因而此处不予赘述。
你暂且只需要知道,所谓的“访问节点”,指的是做一些关于该节点的事情,或是利用该节点做一些事情,具体操作取决于实际情况。
// 访问节点
void visit(Node * p) {
// 在这里做一些关于节点*p的事情
// 具体操作取决于实际情况
}
先/中/后序遍历的递归实现很简单,就是字面意义上的先/中/后,可以说是一目了然。但要想真正透彻地明白,而不是“表面理解”,可能还是需要比较扎实的功底。
// 先序遍历
void traverse_preorder(Node * p) {
if (p != nullptr) {
visit(p);
traverse_preorder(p->left);
traverse_preorder(p->right);
}
}
// 中序遍历
void traverse_inorder(Node * p) {
if (p != nullptr) {
traverse_inorder(p->left);
visit(p);
traverse_inorder(p->right);
}
}
// 后序遍历
void traverse_postorder(Node * p) {
if (p != nullptr) {
traverse_postorder(p->left);
traverse_postorder(p->right);
visit(p);
}
}
调用 即可访问整棵树。如果希望仅访问某棵子树,将该子树的根节点作为调用参数即可。
非递归的实现难度较大,详见下文中的“深入理解”一小节。
至于层序遍历,其本质就是个裸的广度优先搜索,因而此处不予赘述,请直接去学习图论中的广度优先搜索,再回来就能立刻理解。
// 层序遍历
void traverse_levelorder(Node * root) {
// 特判
if (root == nullptr) {
return;
}
// 主循环
queue<Node *> q;
q.push(root);
while (!q.empty()) {
// 出队
Node * p = q.front();
q.pop();
// 访问
visit(p);
// 入队
if (p->left != nullptr) {
q.push(p->left);
}
if (p->right != nullptr) {
q.push(p->right);
}
}
}
另外一种写法如下,代码更短,但是一些会进行毫无意义的入队出队操作,除此以外,该写法和前面的一种是等价的。
// 层序遍历
void traverse_levelorder(Node * root) {
// 主循环
queue<Node *> q;
q.push(root);
while (!q.empty()) {
// 出队
Node * p = q.front();
q.pop();
// 是空子树的情况
if (p == nullptr) {
continue;
}
// 访问
visit(p);
// 入队
q.push(p->left);
q.push(p->right);
}
}
至于一般树的遍历,只有先序遍历、后序遍历和层序遍历三种,因为对于一般树我们无法准确定义“中序”的概念。
# 深入理解
前文已经介绍了先/中/后序遍历的递归实现,较为简单且非常直观,但是如果要用非递归的方式去实现,问题的难度就不是一个档次了,如果你既对先/中/后序遍历的本质没有足够的理解,也没有足够强大的编程能力,你是很难透彻地理解它们的,通常撑死是“表面理解”罢了。
虽然考试不大可能涉及(因为很难),但是在各种面试中,确实有时会出现面试官要求你非递归实现这三种遍历之一的情况,所以非递归实现的方法还是很重要的。
首先我们知道,递归的本质是隐式地调用一个系统栈,并利用栈来存储途径的一些步骤。而先/中/后序遍历的本质是深度优先搜索,因此我们毫无疑问地要借助栈来完成非递归实现。
理解这些非递归实现的关键在于,意识到树上任意一个节点都可以视为某棵子树的根节点,知道递归的本质,并且能理解递归和栈之间的关系。
# 先序遍历的非递归实现
先序遍历是最容易的,我们考虑栈的LIFO性质,我们只需要在访问根节点后,先将其右子节点入栈、再将其左子节点入栈,即可实现根节点-左子树-右子树的访问顺序。
为便于理解,我们稍微解释一下这个过程。初始时根节点入栈。第一轮循环,根节点出栈、访问,右子节点入栈、左子节点入栈。第二轮循环,因为左子节点是后入栈的,所以此时出栈的是根节点的左子节点。如果将其视为左子树的根节点,那么这就是一个等同于“递归”的过程,又是一次根节点出栈、访问。直到某一次轮到某个右子节点出栈,我们也可以将其视为右子树的根节点,同理不予赘述。
// 先序遍历:非递归
void traverse_preorder(Node * root) {
// 特判
if (root == nullptr) {
return;
}
// 主循环
stack<Node *> stk;
stk.push(root);
while (!stk.empty()) {
// 出栈
Node * p = stk.top();
stk.pop();
// 访问
visit(p);
// 入栈
if (p->right != nullptr) {
stk.push(p->right);
}
if (p->left != nullptr) {
stk.push(p->left);
}
}
}
# 中序遍历的非递归实现
我们考虑中序遍历的过程,相当于一路递归左子树,直到左子树为空为止,然后回溯,并先后访问根节点和右子树。
考虑用栈模拟这个一路递归左子树的过程,途径的节点即为每个子树的根节点,将它们全部入栈,直到左子树为空为止,此时我们抵达了一棵子树的尽头。
当左子树为空时,访问栈顶节点并出栈,该节点一定是某一棵子树的根节点。
接下来我们要处理以该节点为根节点的子树的右子树。这里出现了一个问题,你不能想当然地直接将右子节点入栈,仔细思考会发现,这样有时会导致出现死循环,同一个节点反复出入栈,你无法判断什么时候该离开、什么时候该继续递归。
一个不太好的解决方案是用 的额外空间去维护每个节点是否已经被访问过,这显然能帮助我们决定该离开还是该继续递归。当然,我们是有办法不使用这些额外空间的。
我们用一个指针 来维护当前所在子树的根节点。
在一路递归左子树的过程中不断令p = p->left,当p == nullptr时,意味着我们到达了一棵左子树的尽头,终止递归。
而当我们希望处理一棵右子树时,意味着左子树和根节点都已经处理完成了,因此我们可以直接将其抛弃,令p = p->right,也就是说,将问题完全转移到右子树上,这样就避免了前文所述的“无法离开的死循环”的问题。
但是还需要考虑的是,当p->right == nullptr时我们应当怎么做。这意味着我们到达了一棵右子树的尽头,在这种情况下,这意味着该右子树所处的子树已经被遍历完成了。
事实上,我们不需要再做其他的处理,这只是因为此时的行为和到达左子树的尽头时应有的行为恰好是可以用同一份代码解决的。例如下文的图示中的图就是这种情况,可以发现,我们下次取出栈顶就是更上一级的根节点,再令p = p->right进入其右子树,一切都很正常。
为便于理解,下面中给出了该过程的示意图,其中红圈标注节点表示已访问,为蓝色空圈表示p == nullptr,栈的左侧为栈底。
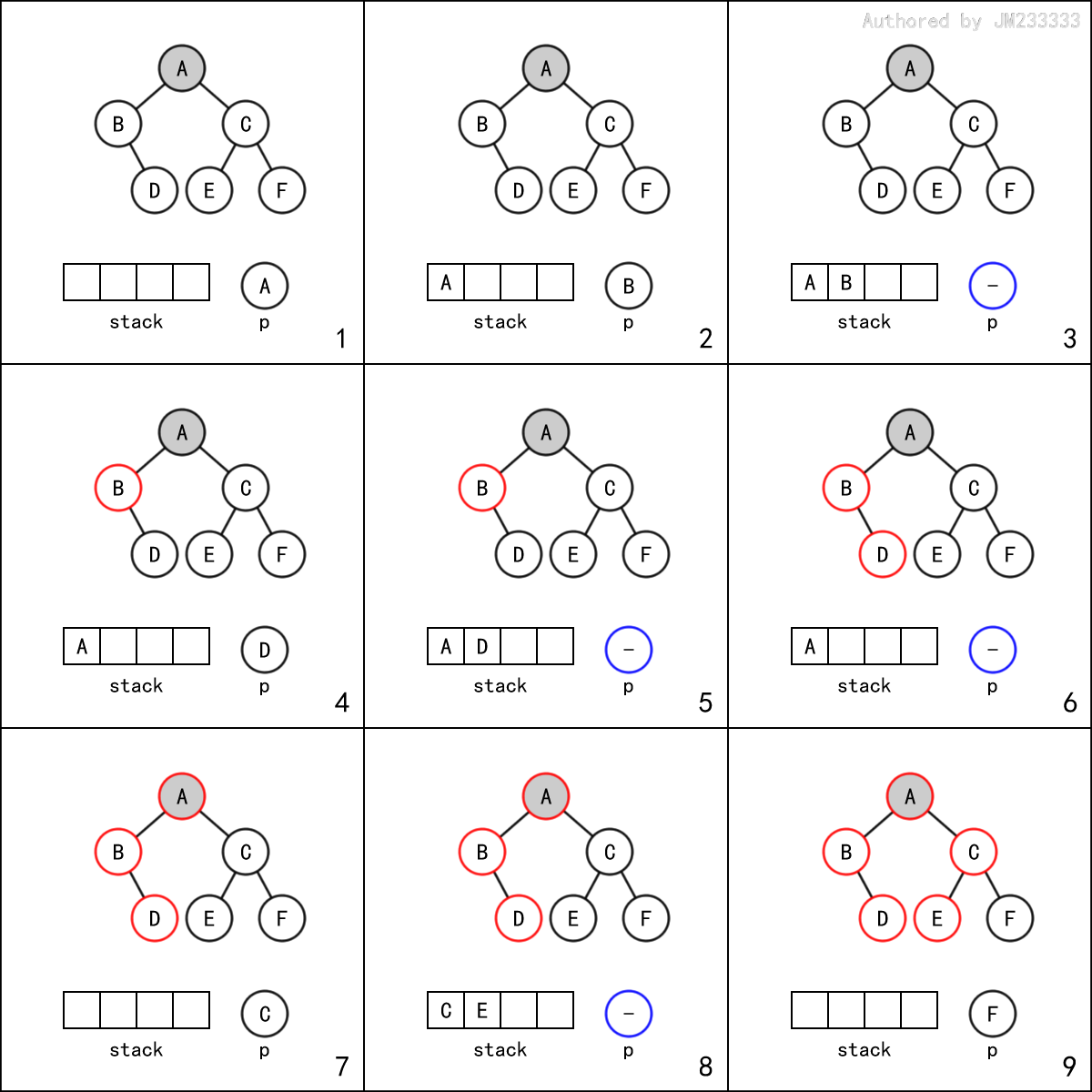
代码实现并不长,但其内在逻辑却并不简单。此外,中序遍历可以将特判省掉,不过这并不是重点。
// 中序遍历:非递归
void traverse_inorder(Node * root) {
// 主循环
stack<Node *> stk;
Node * p = root;
while (!stk.empty() && p != nullptr) {
// 递归左子树
while (p != nullptr) {
stk.push(p);
p = p->left;
}
// 访问根节点,进入右子树
if (!stk.empty()) {
p = stk.top();
stk.pop();
visit(p);
p = p->right;
}
}
}
# 后序遍历的非递归实现
如果我们用两个栈来实现后序遍历的话,难度其实是比中序遍历要低的,并不难理解。
类似于先序遍历,我们考虑栈的LIFO性质,现在我们需要的顺序是左子树-右子树-根节点,将之反过来就是根节点-右子树-左子树。我们交换一下先序遍历中将左子节点和右子节点入栈的顺序,即可实现这一顺序。
而我们需要的是逆序输出,而将序列逆序输出也是栈的基本功能,我们只需要用一个辅助栈来记录每次从主栈中出栈的节点,等主循环结束后,再从辅助栈中依次弹出并访问每个节点即可。
// 后序遍历:非递归
void traverse_postorder(Node * root) {
// 特判
if (root == nullptr) {
return;
}
// 主循环
stack<Node *> stk, out;
stk.push(root);
while (!stk.empty()) {
// 出栈
Node * p = stk.top();
stk.pop();
// 压入辅助栈中
out.push(p);
// 入栈
if (p->left != nullptr) {
stk.push(p->left);
}
if (p->right != nullptr) {
stk.push(p->right);
}
}
// 访问
while (!out.empty()) {
Node * p = out.top();
out.pop();
visit(p);
}
}
但如果仍然只用一个栈来解决问题,也就是只用 的辅助空间而不是 的(虽然其实都是 的空间,但有时面试官会希望你做得更好),那么后序遍历的难度是公认最高的,但其实我觉得它虽然更难想到,但却比中序遍历要更好理解一些。
首先声明,对于教材中的后序遍历的非递归实现,我个人是非常鄙弃的。它在其定义的栈中使用了一个 变量,这本身就是 的额外空间,简直是自作聪明,还不如直接用一个辅助栈解决问题,简单易懂。还请大家将其当作反面教材看待。
后序遍历的顺序是左子树-右子树-根节点,设当前栈顶为 ,那么如果 的左子树和右子树均为空,或是 的左子树和右子树均已遍历完成,则我们可以直接访问 ,并将其出栈。否则,我们将其右子节点和左子节点依次入栈,理由同先序遍历。
关键在于如何判断 的左子树和右子树是否均已遍历完成。这里的实现方法非常精妙,我们用一个指针 来维护上次被访问的节点,当prv == p->left或prv == p->right时,就意味着左子树和右子树均已遍历完成。
这可能有些难以理解,下面给出详细的解释。
首先,在该方法中,树上的每个节点都会被遍历到两次——第一次入栈,第二次出栈。这是很显然的。
考虑某一节点在第一次被遍历到时,其左右子节点均会入栈(如果非空的话),这意味着,在其左右子节点出栈之前,该节点肯定不会第二次被遍历到,而左右子节点出栈就意味着它们已经被访问过。
事实上,这里容易误认为应当仅用prv == p->right判断,这是不对的。之所以需要两个条件取或,是因为右子树可能为空,在这种情况下,我们显然应当用prv == p->left判断。而他之所以不影响左子树为空和左右子树均不为空的这两种情况,是因为在入栈时左子树在上,这意味着,如果我们再次遍历到p,并且prv == p->right,就意味着右子树一定为空,不会出现错判。
此外,注意特判prv == nullptr的情况,此时当前节点肯定不是第二次被遍历到,上述判断是不应进行的。
为便于理解,下面中给出了该过程的示意图,其中红圈标注节点表示已访问, 为蓝色空圈表示prv == nullptr,栈的左侧为栈底。
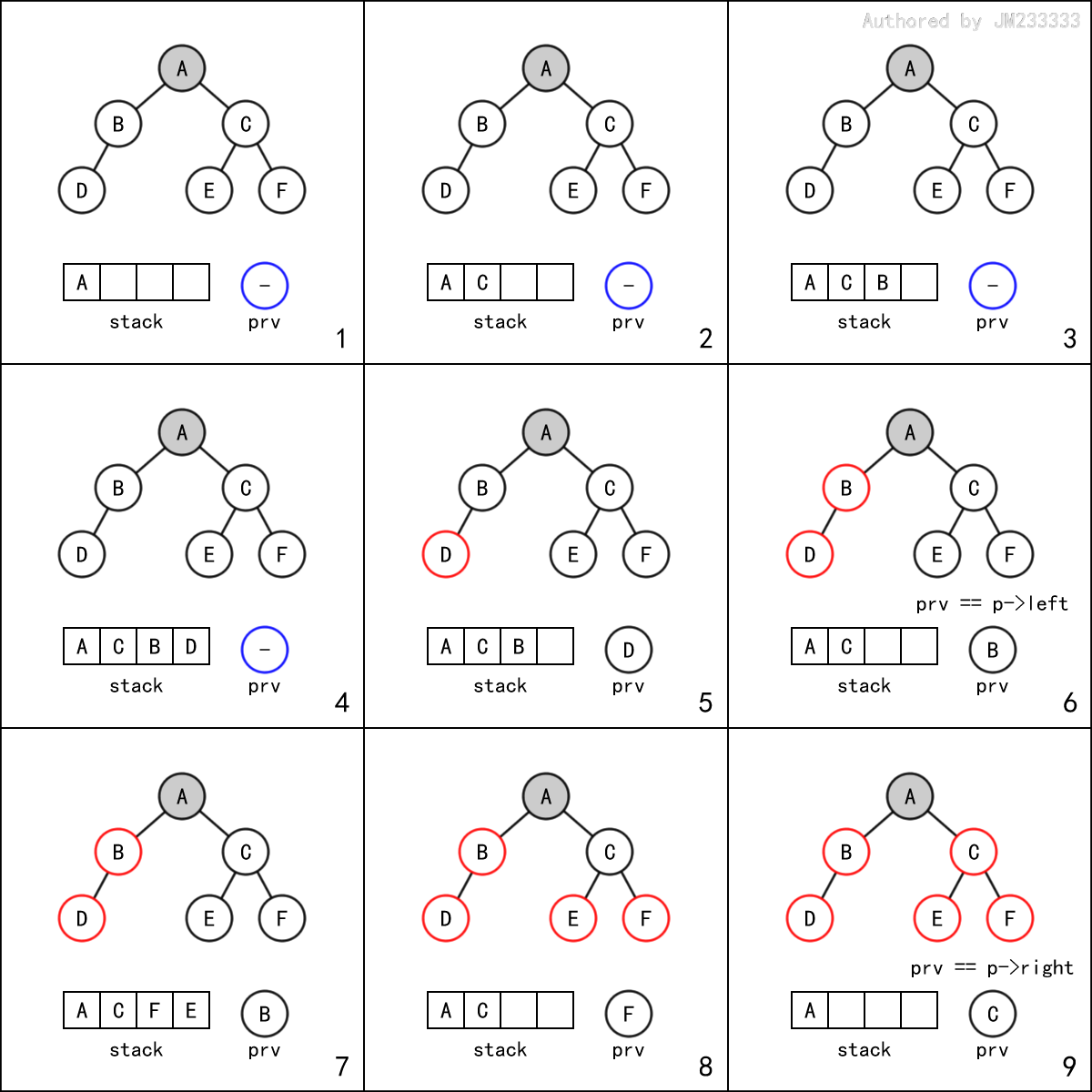
代码实现并不长,但其内在逻辑却并不简单。
// 后序遍历:非递归
void traverse_postorder(Node * root) {
// 特判
if (root == nullptr) {
return;
}
// 主循环
stack<Node *> stk;
stk.push(root);
Node * prv = nullptr;
while (!stk.empty()) {
// 获取栈顶
Node * p = stk.top();
// 判断是否访问
if ((p->left == nullptr && p->right == nullptr) ||
(prv != nullptr && (prv == p->left || prv == p->right))) {
// 出栈
stk.pop();
// 访问
visit(p);
prv = p;
} else {
// 入栈
if (p->right != NULL) {
stk.push(p->right);
}
if (p->left != NULL) {
stk.push(p->left);
}
}
}
}
教材中还有一个三叉链表的先序遍历的非递归实现,我同样非常鄙弃,使用那个 简直毫无意义,除了徒增代码复杂程度以外,实在是没有哪一点比得上直接用栈实现的。还请大家将其当作反面教材看待。
至于一般树的遍历的非递归实现,先序遍历和二叉树基本一致,只需在入栈时逆序遍历子节点指针即可,后序遍历借助辅助栈的实现同理也和二叉树基本一致。
# 扩展
无论是递归实现还是非递归实现的遍历,都使用了 的辅助空间,区别只是使用的是系统栈还是我们自己开辟的栈而已。
事实上,我们可以仅使用 的额外空间就完成二叉树的先/中/后序遍历,即Morris遍历算法。因为这已经超出了本文的难度,故此处不予赘述,详见 Data Structure 知识板块中的 xx - xx 文档。
# 二叉树和一般树的相互转换
有时,我们会希望把一棵一般树转换为二叉树的形式,并且或许不在意各节点的相对位置的改变,显然这有很多种转换方法,但我们希望有一种通用的策略,并且能够逆反而回,实现相互转换,这也就是本节将要介绍的内容。另外,这种转换方法没有什么特殊的理由,不存在什么原理和特殊的优缺点,无需深究,学会这种转换思想就好。
二叉树和一般树的相互转换需要借助左儿子右兄弟表示法,过程非常简单,借助图示很容易就能理解。
# 一般树转换为二叉树
如果该树是用父子节点表示法来表示的,那么我们需要先将其转换为左儿子右兄弟表示法。
将一般树中的所有左儿子指针当作二叉树中的左儿子指针。
将一般树中的所有右兄弟指针当作二叉树中的右儿子指针。
如有必要,再将其转换为父子节点表示法。此时我们得到了一棵二叉树。
# 二叉树转换为一般树
如果该树是用父子节点表示法来表示的,那么我们需要先将其转换为左儿子右兄弟表示法。
将二叉树中的所有左儿子指针当作一般树中的左儿子指针。
将二叉树中的所有右儿子指针当作一般树中的右兄弟指针。
如有必要,再将其转换为父子节点表示法。此时我们得到了一棵一般树。
可以发现,这两个转换过程是互为逆过程的,这样就实现了一个可逆的相互转换。下面给出了这一过程的图示。
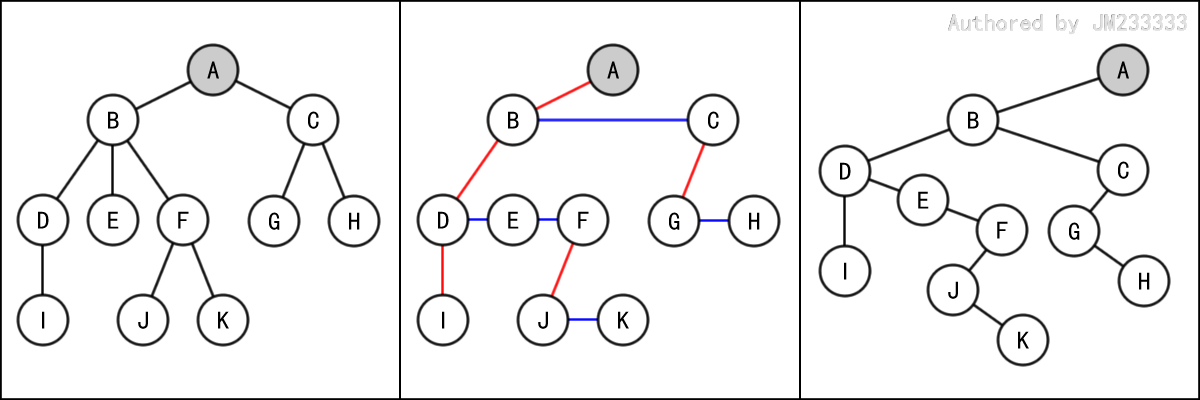
虽然转换的思想很简单,但是具体的代码实现会比较麻烦,此处不予赘述。
# 应用
一棵普通的二叉树的用处不是那么大,通常来说,二叉树更重要的意义是作为许多数据结构与算法的基础存在着。当然,也是存在着普通二叉树的直接应用的。
一个最常见的例子是对算术表达式的存储和表示,树上的所有非叶子节点均为二元运算符,所有叶子节点均为数值。例如(1 + 2) * 3和(6 + 3 * (5 - 1)) / (4 + 2)可以表示为下图所示的二叉树。当然,表示方法往往不止一种,但它们在运算结果上是等价的。
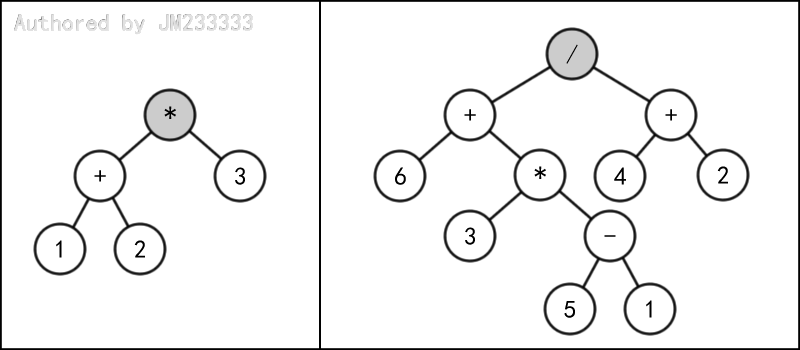
这种表示方法是很有意义的。
首先,比起线性存成字符串来说,它可以很方便地进行算式的修改。
再者,可以发现,对该树进行中序遍历并在遍历过程中适当地添加括号就可以得到原始的算式,或者进行中序遍历直接算出算式的运算结果。而如果线性存成字符串的话,光是考虑括号和各种运算符优先级就已经够麻烦的了。
此外,对该树进行先序遍历可以得到算式的前缀表达式、进行后序遍历可以得到算式的后缀表达式,这也意味着我们用二叉树可以轻易地完成前/中/后缀表达式之间的转换。
如果你不清楚关于前/中/后缀表达式的概念,详见 Various Algorithms 知识板块中的 xx - xx 文档。(该文档未完成)
二叉树及其思想有着极为广泛的应用,并且每一个应用都在数据结构与算法中占据着极其重要的地位,必须掌握,包括二叉查找树、平衡树、二叉堆、哈夫曼树等,因为内容很多,此处不予赘述,将其分割到后续的各个文档中。
- 01
- Reading Papers - Kernel Concurrency06-01
- 02
- Linux Kernel - Source Code Overview05-01
- 03
- Linux Kernel - Per-CPU Storage05-01