 Data Structure 11 - Binomial Heap
Data Structure 11 - Binomial Heap

# 前置知识
在阅读本文档前,请确保你已经掌握堆的基本概念,详见 Data Structure 知识板块中的 05 - Heap 文档。
# 基本概念
二项树 (Binomial Tree) 是一种追加了特殊限制的有根有序树。设 表示高度为 的二项树,则二项树的递归定义如下:
只有 个节点,即根节点;
的根节点的度数为 ,其子树从左到右依次为 。
恰好有 层。
为便于描述,我们设二项树的根节点的深度为 。
二项树 的逻辑结构如下图所示:
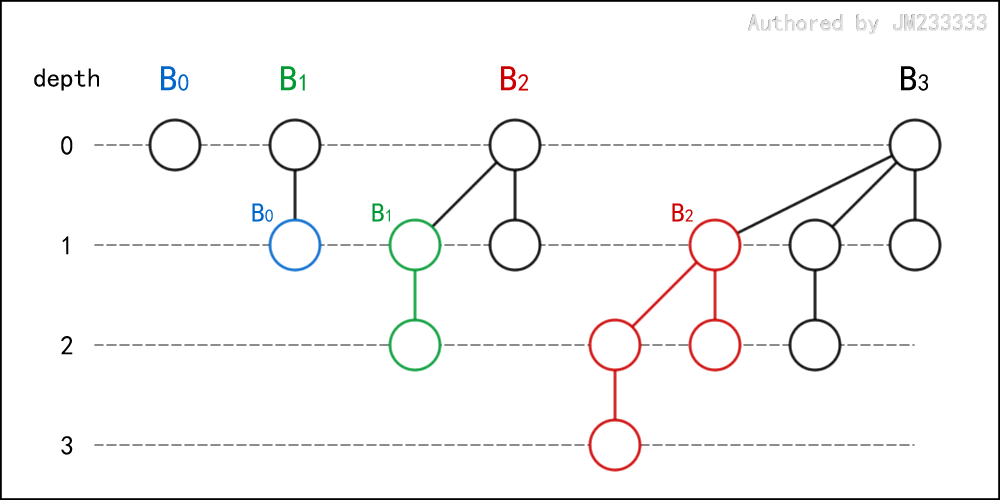
二项堆 (Binomial Heap) 是一种由二项树组成的森林,其中的每棵树都满足堆性质,并且森林中高度为 的二项树最多只有一棵。二项堆的堆顶为所有二项树的根节点中的最值节点。
二叉堆是一种 可并堆 (Mergeable Heap) ,这意味着除了基本的插入操作、查询最值操作和弹出操作外,二项堆还可以高效地支持如下功能:
- 合并操作:将两个二项堆合并为一个,并保持堆性质。
下图是两个二项堆的例子。这是两个大顶堆。
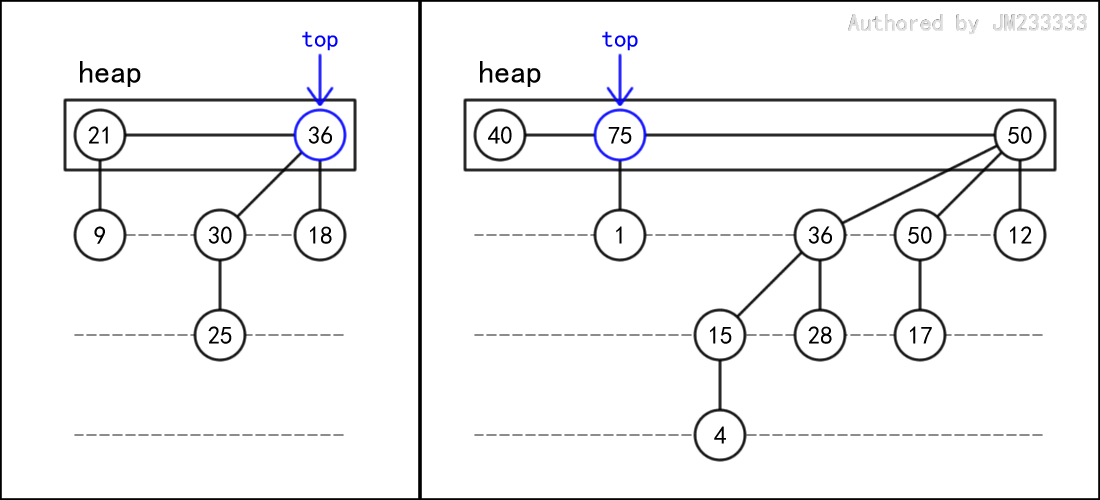
图中的矩形表示一个用于存储二项树的容器。为保证时间复杂度,我们通常要求二项树在容器中按树的深度有序,下文会对此给出详细的解释。
本文中的内容均以大顶堆为例,并在代码示例中使用子节点表示法来表示二项树的节点、使用单链表作为二项树的存储容器:
// 定义
class Node {
public:
int value;
LinkedList children;
public:
Node(int v) : value(v) {}
int degree() {
return children.size();
}
};
// typedef
typedef Node * pNode;
// 定义根节点列表
LinkedList heap = LinkedList();
其中 LinkedList 是封装好的单链表,表中的节点为 LinkedListNode 类型,表中的元素为 pNode 类型(即 Node * 类型)。该类的接口定义如下:
| 接口 | 功能 | 返回值 | 时间复杂度 |
|---|---|---|---|
该表同时需要维护一个 back 指针来支持 的 push_back 操作。不维护 back 指针也可以,使用 push_front 能达到同样的效果,可以保证各种操作的时间复杂度不变差,但是代码会复杂一些,常数时间也会差一些。
事实上,我们亦可使用左儿子右兄弟表示法来表示节点,或是使用动态数组作为存储容器,这并不重要。
注:为了避免在代码示例中使用 STL 容器和迭代器,从而使读者能够着重关注二项堆的原理而不是具体实现,我们决定在文中的代码示例中使用自定义的容器类,而在最后附上了使用 STL list 的代码实现以便于实际应用。
# 原理
# 基本原理
观察和思考易得,二项树具有如下基本性质:
在 中恰好有 个节点。
在 中深度为 的节点恰好有 个。(其实这条大概没什么用)
由上述第一条性质推导可得:
对于一个含有 个节点的二项堆,在 的二进制表示中,每一个 都表示堆中的一棵二项树。例如 ,则二项堆中包含 这 棵二项树。
对于一个含有 个节点的二项堆,其中的二项树不超过 棵。
我们知道任意一个正整数 可以表示为形如 的二进制形式,这也是二项堆被定义为不重复二项树森林的原因,这解决了二项树无法用于表示任意节点个数的问题。此外,我们还可以由此推导证明二项堆各项操作的时间复杂度,具体详见下文。
# 连接操作
连接操作是作为合并操作的子程序存在的,而不是供外部使用的。为了更清楚地讲解合并操作,我们先单独介绍连接操作。
- 连接操作:将两个二项树 合并为 。
连接操作很简单,如下图所示,我们只需要将其中一个 添加到另一个 的根节点的 children 列表中即可。为了保持二项树的堆性质,我们需要将根节点的值较小的二项树作为子树。

现在我们考虑连接操作的正确性。
;;;
下面是连接操作的代码实现,该函数传入两个 的根节点,返回 的根节点。
// 连接
pNode link(pNode from, pNode to) {
// 交换
if (from->value != to->value && !(to->value < from->value)) {
return link(to, from);
}
// 连接
to->children.push_back(from);
return to;
}
# 单树合并操作
二项堆的所有操作都是基于单树合并操作实现的,这是二项堆的核心思想。只要能透彻地理解单树合并操作的实现,就能理解有关二项堆的一切。
单树合并操作:将单独的一棵二项树 合并到一个二项堆 中。为便于描述,下文中我们会用 代指 的根节点列表。
因为在二项堆中,高度为 的二项树最多只有一棵,所以将 并入 中只可能会遇到两种情况:
在 中有且仅有一棵与 高度相同的二项树 ;
在 中不存在与 高度相同的二项树。
前文已经提到过,在 中的二项树是按树的深度有序的。不妨设其为升序,那么我们只需要简单地从前往后遍历 ,即可确定是否存在这样的 :
如果遍历发现一棵二项树 ,则说明不存在与 高度相同的二项树,将 直接插入到对应的位置即可;
如果遍历发现一棵二项树 ,则将 取出与 合并得到 ,并重新尝试将 合并到 中。
由于 是有序的,且合并过程消除了 中所有高度为 的二项树,所以在重新尝试时,我们只需从先前的位置出发继续遍历 即可,无需从头再来。
单树合并操作的示例如下图所示。

合并操作的正确性是显然的,它直接依赖于连接操作的正确性。
由 中的二项树不超过 棵可知:
因为遍历是单向的,所以遍历 的时间复杂度为 ;
因为每次连接都会减少一棵二项树,所以 的连接操作至多执行 次,总的时间复杂度为 。
所以合并操作的时间复杂度为 。
下面是单树合并操作的代码实现。
// 单树合并
void merge(pNode tree) {
// 遍历树根列表
LinkedListNode * p = heap.head;
while (true) {
// 插入
if (p == null || tree->degree() < (p->value)->degree()) {
heap.insert(p, tree);
break;
}
// 连接
if (tree->degree() == (p->value)->degree()) {
tree = link(tree, p->value);
p = heap.erase(p);
}
// 递进
p = p->next;
}
}
# 合并操作
合并操作:将两个二项堆合并为一个。为便于描述,我们定义合并操作为将二项堆 合并到二项堆 中,并将 清空。
一个偷懒的办法是直接遍历 并依次将每个二项树合并到 中。这样并不一定能保证时间复杂度是严格的 ,但是一定不会比 更差,也是可以接受的:
// 合并
void merge(LinkedList & nheap) {
// 遍历
LinkedListNode * np = nheap.head;
while (np != nullptr) {
// 合并
merge(np->value);
// 递进
np = np->next;
}
// 清除
nheap.clear();
}
我们可以用双指针扫描法来优化合并的过程,这样可以保证合并操作的时间复杂度为 。
下面是合并操作的代码实现。
// 合并
void merge(LinkedList & nheap) {
// 初始化
LinkedListNode * p = heap.head;
// 遍历
LinkedListNode * np = nheap.head;
while (np != nullptr) {
// 获取被合并树根
pNode tree = np->value;
// 递进
while (p != nullptr && tree->degree() > (p->value)->degree()) {
p = p->next;
}
// 插入
if (p == nullptr || tree->degree() < (p->value)->degree()) {
heap.insert(p, tree);
continue;
}
// 连接
if (tree->degree() == (p->value)->degree()) {
tree = link(tree, p->value);
p = heap.erase(p);
heap.insert(p, tree);
}
}
// 清除
nheap.clear();
}
关于双指针扫描的详细信息,详见 Fundamental Algorithms 知识板块中的 xx - Two Pointers 文档。
# 查询最值操作
因为二项堆中的二项树不超过 棵,所以我们只需要暴力地遍历 中的所有根节点,并取最值即可,时间复杂度为 ,也是可以接受的。
// 查询最值(暴力)
int top() {
// 主循环
int res = -INF;
LinkedListNode * p = heap.head;
while (p != null) {
// 更新答案
if (res < (p->value)->value) {
res = (p->value)->value;
}
// 递进
p = p->next;
}
// 返回
return res;
}
但是我们可以将这个遍历的过程转移到插入、弹出、合并等操作中。我们用指针 来维护二项堆的堆顶,每次对二项堆进行任意一种修改操作之后,立即遍历 并更新 。这样不仅不会导致这些操作的时间复杂度变差,而且将查询最值操作的时间复杂度优化到了 ,只是其中一些操作的时间常数会变差而已。对于需要大量查询堆顶的场合,该优化的效果非常显著。
下面是查询最值操作的代码实现,其中 update_top 函数是对查询最值操作的优化,在对二项堆进行任何修改之后必须立即调用此函数。
// 定义堆顶指针
LinkedListNode * p_max = nullptr;
// 查询最值
int top() {
return (p_max->value)->value;
}
// 更新最值
void update_top() {
// 初始化
p_max = nullptr;
// 主循环
LinkedListNode * p = heap.head;
while (p != null) {
// 更新
if (p_max == nullptr || (p_max->value)->value < (p_max->value)->value) {
p_max = p;
}
// 递进
p = p->next;
}
}
# 插入操作
当我们要插入一个值 时,只需用 构建一个只有一个节点的二项树 ,然后将 合并到二项堆中即可。
插入操作的时间复杂度为 。
下面是插入操作的代码实现。
// 插入
void push(int value) {
// 单树合并
merge(new Node(value));
// 更新最值
update_top();
}
# 弹出操作
当我们要弹出堆顶时,对于当前为最值的二项树 ,我们将其根节点删除,并将其子节点列表合并到 中即可。
弹出操作的时间复杂度为 。
下面是弹出操作的代码实现。
// 弹出
void pop() {
// 获取子节点列表
pNode p = p_m->value;
LinkedList nheap = p->children;
// 弹出
heap.erase(p_m);
p_m = nullptr;
// 合并
merge(heap, nheap);
// 清除
delete p;
// 更新最值
update_top();
}
# 修改键值操作
对于大顶堆,该操作为增大键值操作;对于小顶堆,该操作为减小键值操作。事实上,无论是大顶堆还是小顶堆,都可同时以 的复杂度实现增大键值和减小键值操作,但这在其它一些堆中并不通用,且原理又基本相同,因而就不赘述了,读者可自己推广。本文以大顶堆为例,故本节将介绍增大键值操作的原理。
修改键值操作即对堆内指定节点的键值进行修改。该操作一般需与其它数据结构配合使用,因为在堆中查找指定节点通常是 的,所以要想实际运用修改键值操作,通常需要用其它数据结构维护堆中节点的指针或引用,以便在需要时快速获取指定的节点。
假设我们已经取得指向指定节点的指针,增大其键值后,我们只需将修改后的键值与父节点的键值进行比较,并判断是否破坏了堆性质,如果破坏则与父节点交换,然后递归处理,直到满足堆性质为止。该过程很像二叉堆的筛选操作。
考虑二项堆中二项树高度最高的情况,即只有一棵二项树,因为在 中恰好有 个节点,所以这一棵二项树必为 ,且 恰为 的整数幂次。又因为 的高度为 ,所以二项堆中二项树的最大高度是 的,所以修改键值操作的时间复杂度为 。
下面是修改键值操作的代码实现。
// 增大键值
void increase_key(Node * node, int value) {
// 增大键值
if (node->value > value) {
// error;
}
node->value = value;
// 筛选
while (node->parent != nullptr && node->value > node->parent->value) {
swap(node->value, node->parent->value);
node = node->parent;
}
}
修改键值操作最常见的应用是在 Dijkstra 算法和 Kruskal 算法中。
# 优缺点分析
作为可并堆的一种,除了堆的基本操作外,二项堆还支持对多个堆的快速合并,在特定场合可以发挥重要作用。它的另一个优点是可以将查询堆顶最值的操作优化到 。
遗憾的是,二项堆本身的地位非常尴尬。与左偏树相比,二项堆的代码实现要复杂不少;与斐波那契堆相比,二项堆的时间复杂度则逊色一筹。这使得平时实际应用二项堆的情况较少。
但是学习二项堆仍然是有意义的,因为斐波那契堆实际上借鉴了很多二项堆的思想,先学习二项堆再学习斐波那契堆可以使学习曲线变得平滑,对部分人的思维方式来说,直接学习斐波那契堆可能会感到有些困难。
- 01
- Reading Papers - Kernel Concurrency06-01
- 02
- Linux Kernel - Source Code Overview05-01
- 03
- Linux Kernel - Per-CPU Storage05-01