 Data Structure 07 - Disjoint-Set Union
Data Structure 07 - Disjoint-Set Union

# 前置知识
在阅读本文档前,请确保你已经掌握树的基础知识,并且了解二叉查找树的退化问题及平衡树的基本概念,详见 Data Structure 知识板块中的 06 - Self-Balancing Binary Search Tree 文档。
# 基本概念
并查集 (Disjoint-Set Union) 在逻辑上是一个森林,它可以处理若干个不相交子集的合并和查询问题。
例如,初始时有 个孤立的节点,并查集提供将这些点合并为若干个不相交集,以及查询某个节点所属集合的编号的功能。
为便于描述,设节点编号为 。
假设你已经掌握树的基础知识,那么森林对你来说应当是很简单的,因此这里就不给出逻辑示意图了。
# 原理
并查集的原理非常简单,建议配合代码去理解其原理,通常不会遇到什么理解上的困难。
朴素的并查集只维护一个 信息,设 表示节点 所属集合的编号。许多资料也将其名字记为 或 。这两种命名都是有其各自的道理的,详见下文。
首先,这里所说的集合编号仅仅是一个随意的代号,通常我们不会关心这个编号具体是多少,而只关心 。
然后,每个集合都是以类似于有向有根树的形式存在的,集合的编号指的就是根节点的节点编号。集合内每个节点都有一条指向父节点的边,其中根节点的这条边指向自己。也就是说,并查集事实上是在维护一个森林,所谓的 其实就是 的父节点的编号。根据树的知识,很容易就能理解并查集的操作。
我们当然可以用指针和动态开辟节点的方式来实现并查集,就像实现一棵树一样,但是许多情况下,我们往往只用一个数组来实现并查集:
// 定义
const int MAX = ...;
int belong[MAX];
下文的代码示例也将使用这种实现方式,因为它简单易懂。
# 基本操作
并查集的基本操作包括:初始化、查询、合并。
# 初始化
初始化,即 :通常会初始化所有 ,表示初始为 个孤立节点。当然,根据具体情况,未尝不会有其他的初始化方法,根据具体情况而定。
初始化的代码实现如下:
// 初始化
void initialize(int n) {
for (int i = 1; i <= n; i ++) {
belong[i] = i;
}
}
# 查询操作
查询操作,即 :查询节点 所属集合的编号。
容易想到只需不断令 ,直到发现 时,表明 已被迭代为其所属集合的根节点,即为集合的编号。
并查集本质上就是一个森林,因此查询根节点的过程事实上就是在一棵树上从叶子节点出发回到根节点的过程,非常简单。
查询操作的递归实现如下:
// 查询
int find(int x) {
if (belong[x] == x) {
return x;
}
return find(belong[x]);
}
查询操作的非递归实现如下:
// 查询
int find(int x) {
while (belong[x] != x) {
x = belong[x];
}
return x;
}
# 合并操作
合并操作,即 :将节点 所属集合与节点 所属集合合并。
这只需令 即可。
注意不能写成 ,因为 操作是将两个集合合并,而不是将 移入 所处的集合中。当然,令 亦可。
合并操作的代码实现如下:
// 合并
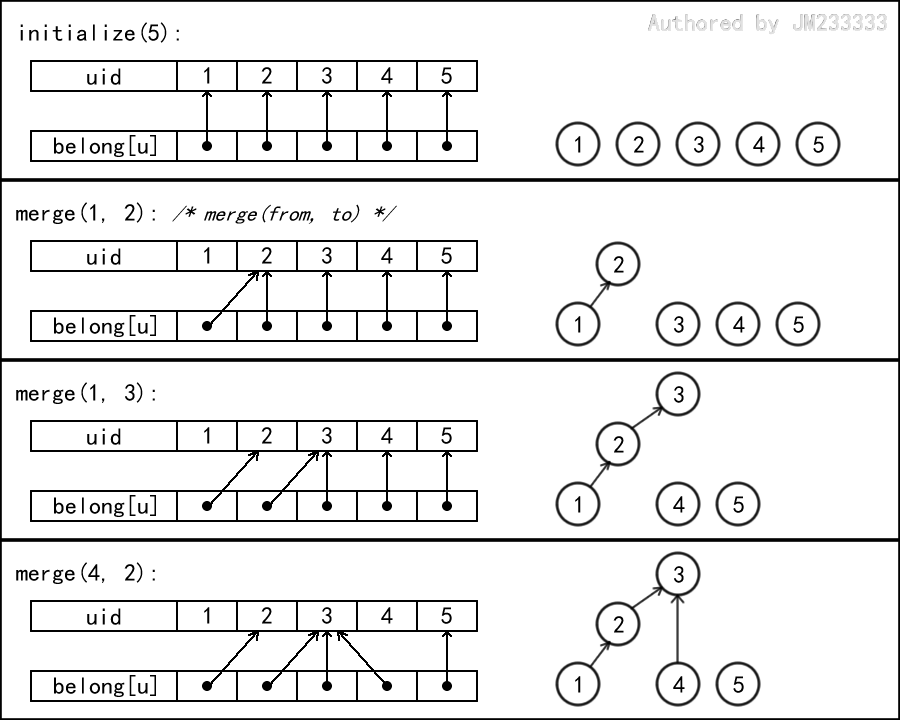
void merge(int x, int y) {
int rx = find(x), ry = find(y);
if (rx != ry) {
belong[rx] = ry;
}
}
下面给出若干次合并操作的示例图。
# 优化
# 并查集的退化
细心思考可以发现,这样简单实现的并查集是有问题的。类似于二叉查找树,特殊构造的数据可以将其结构卡成一条链,如下图所示,进行 次查询操作的最坏时间复杂度为 。
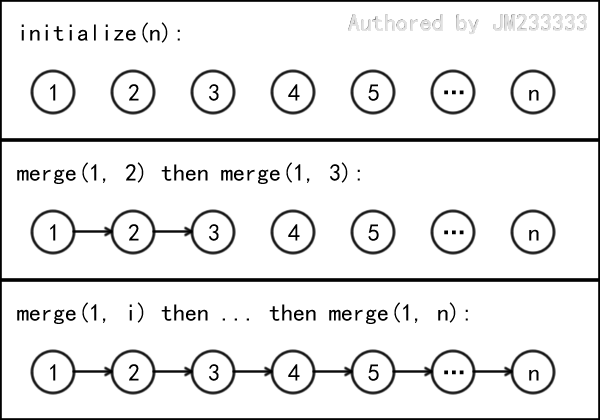
也就是说,类似于二叉查找树的改进方法(如平衡树),我们也需要一些方法来防止时间复杂度的退化。换句话说,朴素的并查集是没有实用价值的。
初学者无需纠结加了各项优化后的时间复杂度具体是怎么算出来的,只需要知道它很高效即可。
# 路径压缩
对查询操作的优化:路径压缩。
设 表示节点 所属集合的根节点。在查询的过程中,对于被访问的每个节点 ,我们令 。这样一来,我们就可以保证每个节点只会被间接访问一次。通俗地讲,任何一个长链都会在一次被查询之后被打散,链上的各个节点都会变成根节点的直接子节点,避免了多次访问长链造成的时间复杂度退化。
这一优化可以保证进行 次查询操作的最坏时间复杂度为 。
路径压缩优化的查询操作的代码实现如下:
// 查询
int find(int x) {
if (belong[x] == x) {
return x;
}
belong[x] = find(belong[x]);
return belong[x];
}
# 按秩合并
对合并操作的优化:按秩合并。
我们另外维护一个 数组,设 表示以 为根节点的子树上节点的最大深度,称为以 为根节点的集合的秩。初始时令所有的 。
在合并时,我们总是保证 ,然后令 。
根据启发式合并的原理,这一优化可以保证进行 次查询操作的最坏时间复杂度为 。
按秩合并优化的合并操作的代码实现如下:
// 初始化
void initialize(int n) {
for (int i = 0; i <= n; i ++) {
belong[i] = i;
rnk[i] = 0;
}
}
// 合并
void merge(int x, int y) {
int rx = find(x), ry = find(y);
if (rx != ry) {
if (rnk[rx] > rnk[ry]) {
swap(rx, ry);
}
belong[rx] = ry;
rnk[ry] = max(rnk[ry], rnk[rx] + 1);
}
}
# 结合使用
同时使用路径压缩和按秩合并。
可以证明,同时使用路径压缩和按秩合并的策略,查询操作的均摊时间复杂度为 ,其中 函数为反阿克曼函数,可以证明 ,因此进行 次查询操作的时间复杂度已经是近似线性的,效率非常高。
# 应用
(unfinished)
- 01
- Reading Papers - Kernel Concurrency06-01
- 02
- Linux Kernel - Source Code Overview05-01
- 03
- Linux Kernel - Per-CPU Storage05-01