 Data Structure 01 - Linear List
Data Structure 01 - Linear List

# 前置知识
在阅读本文档前,请先阅读数据结构的整体介绍文档,详见 Data Structure 知识板块中的 00 - Introduction 文档。
# 基本概念
线性表是最基本的一类数据结构。虽然线性表的相关知识很多,但是其难度却很小。
线性表 (Linear List) 指的是由有限个具有相同特性的数据元素组成的线性序列。线性表是一个统称,通常我们用它表示几个基本的线性数据结构的统称,这是一个抽象定义,因此讨论如何在实际情况中使用“线性表”是没有意义的。这里的“线性”指的是逻辑结构。
从物理结构的角度上,我们将线性表分为顺序表和链表两大类。从功能受限的角度上,除了非受限线性表以外,我们可以将线性表分为栈和队列两大类。
本文讲述顺序表和链表,受限线性表(例如栈和队列等)的知识详见 Data Structure 知识板块中的 02 - Restricted Linear List 文档。
# 顺序表
# 概念
顺序表 (sequential list, or array) 指的是存储在连续空间内的线性表,例如我们熟知的数组就是一种最简单的顺序表。
当然,这里指的是一维数组,因为虽然静态分配的数组的物理结构一定是线性连续的,但是动态分配的多维数组可未必是,而且多维数组的逻辑结构并不是线性的,我们更关注的是逻辑结构。
为方便起见,下文中我们均会用“数组”一词指代一维数组,敬请注意。
# 定义
顺序表的数组定义很简单:
// 定义
const int MAX = ...;
int arr[MAX];
int n = 0;
当然,你也可以动态开辟一块连续的内存,在逻辑上并没有区别:
// 定义
const int MAX = ...;
int * arr = new int[MAX];
int n = 0;
// 销毁
delete[] arr;
其中 为事先知晓的最大表长, 为当前表长,即表中元素个数。
顺序表中的每个元素都有且仅有唯一的索引值,并且这些索引值是线性递增的。也就是说,给定一个下标 ,我们可以唯一地得到 所对应的元素 ,当然,这个下标不能越界。这意味着顺序表支持快速的随机访问,想想数组,你可以 地得到任意一个下标所对应的元素,这并不难理解。
注意,这里的随机访问仅包括修改和访问,并不包括插入和删除。
// 修改
void modify(int index, int value) {
arr[index] = value;
}
// 访问
int at(int index) {
return arr[index];
}
为便于描述,我们规定表长为 ,元素下标为 。
# 优缺点分析
顺序表的优点很明显,无论如何,以 的代价进行 随机访问 (random access) 常常是很有用的。所谓的随机访问,指的是对于任意给出的索引 ,获取对应元素 的能力。当然,索引也可能是一个二元组(例如在二维数组中)或是非整数值(例如在哈希表中)。注意,随机访问中的“随机”一词并不是概率论中的随机的概念,而是表示随意、任意的意思。
或许只接触过数组的你会对此感到茫然,这也算个优点?没关系,你可以先保留疑惑,以后再回来细细感受。事实上,在许多数据结构中,这并不是一件容易做到的事情,为了支持一些其他操作的效率,高速随机访问常常会被放弃。
但是很遗憾,顺序表的缺点也很明显。
首先,如果你希望使用顺序表,你不得不预先知道表中元素的个数(或是至少知道元素个数的确切上界),否则你会面临困境——如果数组开得太小了,则会导致段错误,反之如果数组开得太大了,又会导致浪费大量的空间。看起来开大些总是没错的,然而当你连一个大概的上界都不知道的时候,你应该开到 还是 呢?总不能一次次去试出来吧?
事实上,上面的问题尚且可以根据实际情况通过一些技巧来弥补解决,但是另一个致命的问题就没办法很好地解决了。如果你希望在顺序表中进行随机插入和删除,例如把一个数 插入到数组的第 位上,那么你不得不把 挪移到 处,然后令 。这意味着单次插入和删除的时间复杂度为 。所以如果你需要进行频繁的随机插入和删除操作,那么使用顺序表恐怕不是一个好主意。
# 基本操作
顺序表的插入操作的实现方法并不局限,你可以定义插入操作为“在 处插入”或是“在 后面插入”,这并不重要。下面的代码是“在 处插入”的定义。同样地,删除亦是如此,下面的代码是“删除 ”的定义。
// 插入
void insert(int index, int value) {
for (int i = n; i >= index; i --) {
arr[i+1] = arr[i];
}
arr[index] = value;
n ++;
}
// 删除
void erase(int index) {
for (int i = index; i <= n-1; i ++) {
arr[i] = arr[i+1];
}
n --;
}
当然,如果你不介意破坏顺序表中其他元素的相对顺序,那么你自然可以在 的时间内完成插入和删除。或者,实际情形允许你使用懒惰删除技术并且不影响问题的解决,我们也可以规避掉这一缺陷。然而遗憾的是,我们并非总是能如此,更多的时候我们不希望破坏顺序或是在表中留下一些无用的废弃位置。
// 破坏性插入
void bad_insert(int index, int value) {
arr[n+1] = arr[index];
arr[index] = value;
n ++;
}
// 破坏性删除
void bad_erase(int index) {
arr[index] = a[n];
n --;
}
// 懒惰删除
void lazy_erase(int index) {
// ensure (TAG_LAZY is never used)
// then you can distinguish TAG_LAZY from normal values.
// for example, if you know that arr[i] ∈ [1, 100], just let TAG_LAZY = 10000.
static const int TAG_LAZY = ...;
arr[index] = TAG_LAZY;
}
但是,顺序表在表尾处的插入和删除是 的,不过你不能在表头处这么做,这并不难理解。
// 表尾处插入
void push_back(int value) {
arr[++n] = value;
}
// 表尾处删除
void pop_back() {
n --;
}
# 总结
| 数据结构名称 | 逻辑结构 | 物理结构 | 额外空间复杂度 |
|---|---|---|---|
| 顺序表 | 线性结构 | 顺序存储 |
——
| 基本操作 | 功能 | 时间复杂度 |
|---|---|---|
| 在处插入 | ||
| 在表尾处插入 | ||
| 删除 | ||
| 删除表尾元素 | ||
| 令 | ||
| 求的值 |
# 顺序表的扩展
前文中提到过,如果你希望使用顺序表,你必须预先知道表的大小。这一问题尚且可以通过一些高级的技巧来弥补解决。因为这已经超出了本文的难度,故此处不予赘述,详见 STL 知识板块中的 vector 文档。
# 顺序表的应用
至于顺序表的应用,那不就是数组的应用吗?顺序表的应用实在是太过普遍和不可替代了,我想应该不需要再列举了吧。
# 链表
# 概念
链表 (linked list) 指的是存储在非连续空间内的线性表,它在逻辑上是线性的,但是在物理上,链表中的每个元素都存储在互不相关的空间中。
对于会阅读本文的人群来说,数组必定人人皆知,而链表则未必如此,因此我们先介绍一下链表的概念。
链表还可以分为单链表、双向链表、循环链表等,但是在未指明的情况下,“链表”一词被用于狭义地指代单链表,也就是说,当我们讨论链表时通常是在讨论单链表,除非事先说明。本文中也会遵循该习惯,敬请注意。
本文中着重介绍的也是单链表,其他链表会在后文中简要介绍,因为掌握了单链表以后,其他链表也很容易就能掌握,所以不会耗费我们很多篇幅。
# 定义
一个链表由若干个节点组成,每个节点存储一个数据单位,并且持有一个 指针,指向该节点的后继节点。此外,每个链表都有一个 指针,指向链表的首节点。初始时令 ,表示链表为空。
// 定义
class Node {
public:
int value;
Node * next;
public:
Node() : value(0), next(nullptr) {}
Node(int v) : value(v), next(nullptr) {}
};
Node * head = nullptr;
链表的逻辑结构如图所示。习惯上,我们用一个分成两块的矩形来表示链表中的一个节点:左块表示数据,右块表示指针域。
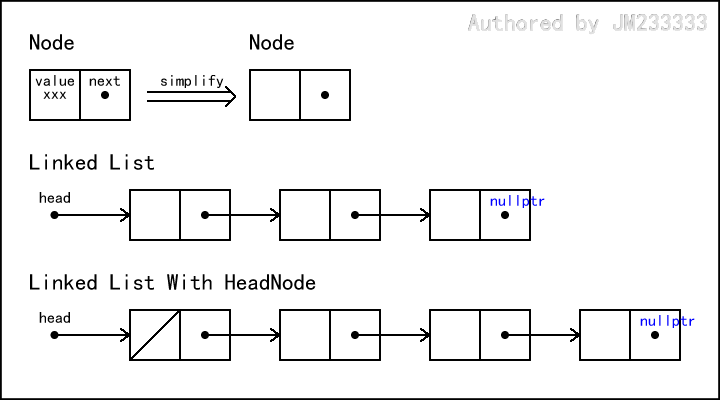
每个节点的 指针都指向其后继节点,若 则表示当前节点为表尾节点。
有些链表的实现会使用头节点,即在链表的表头放置一个固定的、不存储任何数据的节点。这并不是必须的,它的作用是方便我们对表头元素进行操作,下文会对此给出详细说明。
注意区分头节点和头指针,头节点不是必须的,而头指针是每个链表都必须要有的。
// 定义:带头节点的链表
class Node {
public:
int value;
Node * next;
public:
Node() : value(0), next(nullptr) {}
Node(int v) : value(v), next(nullptr) {}
};
// the value of headnode doesn't matter.
// it is easy to ensure that you will never use it.
Node * head = new Node(NULL);
# 优缺点分析
链表的优点是很明显的,就是在一定程度上能够支持 的随机插入和删除。
我们可以在链表的表头或表尾处进行 的插入或删除(如果额外维护一个表尾指针的话),而顺序表则只能在表尾这么做。
此外,如果你能给出指向待插入或待删除的节点位置的指针,那么我们甚至可以在链表的任意位置进行 的插入或删除,而顺序表则无法做到这一点。
问题在于,你必须给出这个指针,如果你给出类似“删除从表头起的第 个节点”这样的要求,操作的时间复杂度仍为 ,并不比顺序表更好。这里一定要分清楚,不要死记硬背“链表的插入删除是 的”,这种说法事实上是不准确的、略微歧义的。
遗憾的是,链表的缺点也是很明显的,我们不能对链表进行随机访问。访问表中任意元素的时间复杂度为 ,除非你事先持有指向目标节点的指针。
链表的另一个不那么重要的缺点是,他会额外耗费一倍的空间用于存储每个节点的指针域。因为现代计算机的内存已经足够大,在适合使用链表的时候,我们是不必顾忌这个尚可接受的空间浪费的。
# 基本操作
下面我们详细解释链表如何进行插入和删除操作。链表操作的代码实现一直是初学者的噩梦之一,个人的经验是,首先弄清楚插入和删除操作的原理,然后在写代码的时候,先用纸笔去画清楚各个指针的变化情况,再去写代码,这样就要容易得多。
# 插入操作
链表的插入操作如图所示,这里我们定义插入操作为“在 的后继处插入”。
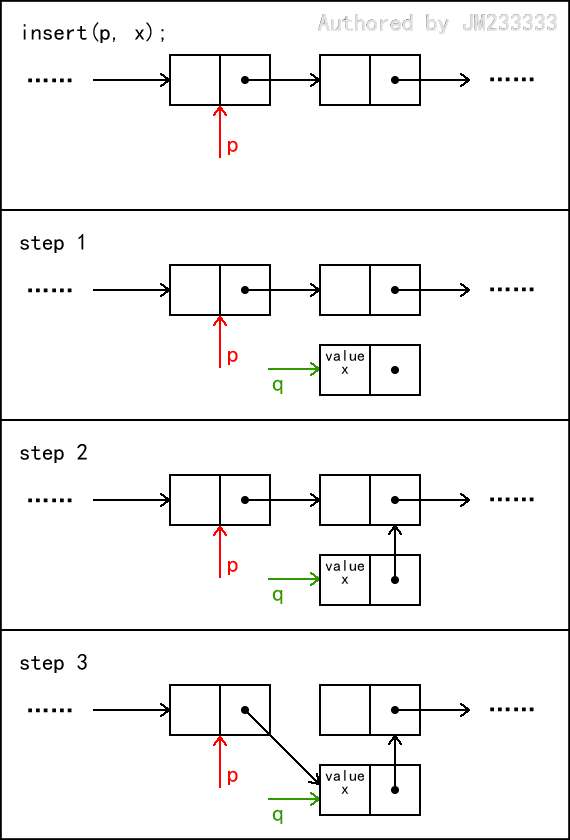
首先,我们需要为待插入元素创建一个新的节点,设为 q 。
接下来,我们需要把 q 放到 p 和 p->next 这两个节点之间,那么 p 的后继将是 q , q 的后继将是 p->next 。
这里的易错点是,我们必须先令 q->next = p->next ,再令 p->next = q 。如果顺序不对会导致写出的代码等价于 q->next = q ,错误地形成自环,未能正确地插入节点。
// 插入(不完整的)
void insert(Node * p, int value) {
if (p == nullptr) {
// throw an error
}
Node * q = new Node(value);
q->next = p->next;
p->next = q;
}
插入操作的过程就这么短,然而实际上它并没有这么简单。
第一个问题,注意到我们定义插入操作为“在 的后继处插入”,这意味着我们无法在表头处插入。
第二个问题,当链表为空时插入节点,此时 ,那么 head->next 显然是没有意义的。
有人可能会想到,为什么不定义插入操作为“在 处插入”?仔细观察上述的插入过程,可以发现,如果你希望在 处插入,那么你不得不获取 的前继节点,而单链表的节点中只含有指向后继节点的指针,这意味着你不得不从表头出发遍历一遍链表,显然这是不值得的。可见链表的插入不像顺序表那么随心所欲,所以我们经常定义插入操作为“在 的后继处插入”而不是“在 处插入”。
回到刚才的问题。
一种解决方案是,对于第一个问题,我们传入 insert(nullptr, value) 表示在表头处插入,此时我们需要进行特殊处理,先令 q->next = head ,再令 head = q 。可以发现,第二个问题也被顺便解决了,因为链表为空时插入节点即是在表头处插入节点,而 q->next = head 即为 q->next = nullptr ,一切正常。
// 插入
void insert(Node * p, int value) {
Node * q = new Node(value);
if (p == nullptr) {
q->next = head;
head = q;
} else {
q->next = p->next;
p->next = q;
}
}
而另一种解决方案,就是使用前文提到的带头节点的链表。因为头节点是不存储数据的,且 始终指向头节点,这意味着我们不可能会在头节点处插入新节点,在头节点的后继节点处插入就可以满足我们的需求——它确实被插入到了所有数据的最前面。此外,我们也不会面临 的情况,因为哪怕链表为空,头节点也是存在的。
// 插入:带头节点的链表
void insert(Node * p, int value) {
if (p == nullptr) {
// throw an error
}
Node * q = new Node(value);
q->next = p->next;
p->next = q;
}
两种解决方案没有优劣之分,看个人喜好即可。
# 删除操作
链表的删除操作如图所示,这里我们定义删除操作为“删除 的后继节点”。
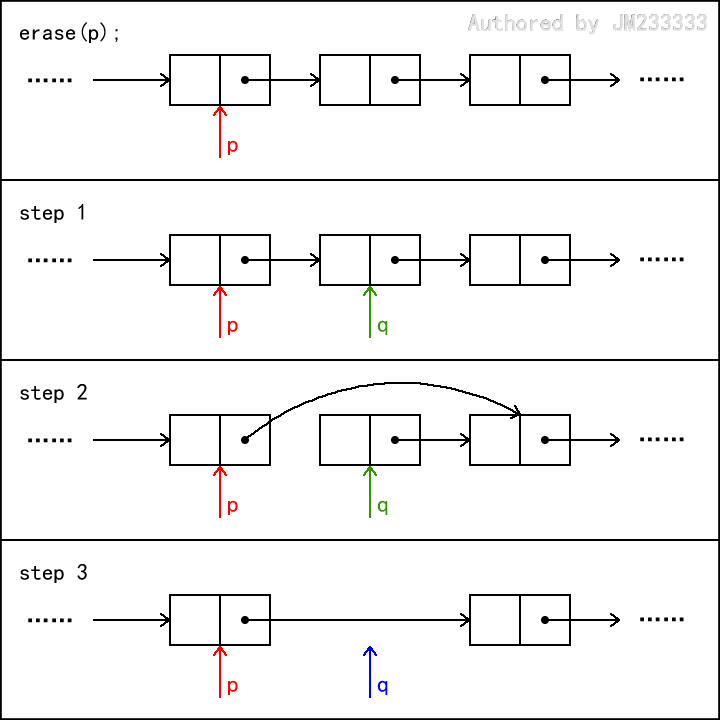
有人可能会觉得,我们直接令 p->next = p->next->next 就可以了。从逻辑上来看,这的确没什么问题,但是不要忘了,你是用 new 为节点分配的内存,这会直接导致你丢失那个被删除的节点,造成内存泄露。你必须保证用 delete 释放它,除非你使用智能指针,或是使用一些自动管理内存的编程语言。
首先,我们令 q = p->next ,记住那个将要被删除的节点。
然后,我们令 p->next = p->next->next ,执行 delete q ,完成内存的释放。同样有执行顺序的问题,不能先 delete q ,否则会造成链表的断裂丢失。
// 删除(不完整的)
void erase(Node * p) {
if (p == nullptr) {
// throw an error
}
Node * q = p->next;
p->next = p->next->next; // or p->next = q->next;
delete q;
}
删除操作的过程就这么短,然而就和插入一样,实际上它也没有这么简单。
因为删除和插入的问题很多是类似的,对于操作这么定义的理由也是相同的,故此处不再赘述。
第一个问题,如果用户传入的是指向表尾节点的指针,这一删除操作显然是非法的,因为 p->next == nullptr 。如果无法保证用户输入的合法性,你可能就需要做出特殊处理,否则这将导致段错误。
第二个问题,如果用户试图删除表头节点,你必须做出特殊处理。
// 删除
void erase(Node * p) {
if (p == nullptr) {
Node * q = head;
head = head->next; // or head = q->next;
delete q;
} else if (p->next != nullptr) {
Node * q = p->next;
p->next = p->next->next; // or p->next = q->next;
delete q;
} else {
// throw an error
}
}
类似于插入,我们同样可以使用带头节点的链表,这样只需特殊处理第二个问题即可。
// 删除:带头节点的链表
void erase(Node * p) {
if (p == nullptr || p->next == nullptr) {
// throw an error
}
Node * q = p->next;
p->next = p->next->next; // or p->next = q->next;
delete q;
}
两种解决方案没有优劣之分,看个人喜好即可。
事实上,我们在很多情况下只会在表头处插入和删除,毕竟我们通常不会去保持那么多个表内节点的指针。
即便如此,给定指针即可进行 操作仍然是链表的一个重要的优点,因为很多情况下我们需要遍历整个线性表,然后根据情况在过程中进行增删改查,这时链表就可以发挥最大的作用,如果使用顺序表则效率要低得多,毕竟在遍历的过程中我们始终持有着表内节点的指针。
然而遗憾的是,如果需要在表内频繁地进行随机的增删操作的话,链表和顺序表是一样低效的。
# 修改和查询操作
最后是链表的修改和查询。
类似于插入和删除,如果我们希望“修改从表头起的第 个节点”,那么时间复杂度为 ,如果给定对应的指针,那么时间复杂度为 。其代码实现与插入和删除类似,所以不予赘述。
# 遍历
下面给出遍历并输出链表的代码,很简单,不予赘述。
// 遍历
void traverse() {
printf("head -> ");
for (Node * p = head; p != nullptr; p = p->next) {
printf("[%p](%d) -> ", p, p->value);
}
printf("[nullptr]()\n");
}
# 总结
| 数据结构名称 | 逻辑结构 | 物理结构 | 额外空间复杂度 |
|---|---|---|---|
| 链表 | 线性结构 | 链式存储 |
——
| 基本操作 | 功能 | 时间复杂度 |
|---|---|---|
| 在的后继处插入 | ||
| 删除的后继 | ||
| 令 | ||
| 求第个元素的值 |
# 链表的扩展
前文中提到过,链表还可以分为单链表、双向链表、循环链表等,这里对双向链表和循环链表做一个简单的介绍。
在双向链表中,每个节点除了维护指向后继节点的指针以外,还维护指向前继节点的指针。这也可以很好地解决前文中提到过的插入和删除的一些特殊情况,且方便我们在链表中来回移动。另外,这意味着双向链表浪费的空间比链表还要大,因而除非必要(例如可能需要倒序遍历表中元素),我们还是会使用单链表。
在循环链表中,表尾节点的 指针将会指向表头节点。这样做可以让表处理更加方便灵活,不过它并不常用,也不难,在初学阶段稍作了解即可。
# 静态链表
接下来我们要介绍链表的静态实现,即用数组来实现链表。
或许你会觉得这有些匪夷所思,然而事实上静态链表非常有用。此外,静态链表的存在也告诉我们,链表的思想本身比起链表的实现更加重要。
首先需要知道的是,要想使用一个静态链表,我们必须为它同时维护两条链表,一条为当前实际的链表,一条存储着所有的未被使用的节点编号,称为空闲表。否则,在进行删除操作后,我们会丢失空闲内存的信息。当然,除非你保证不会进行删除操作(除清空全表以外),那么我们就不需要去维护第二条链表了,当前表长以外的部分即是所有的空闲内存。至于这个空闲表具体如何维护,详见下文。
其次需要知道的是,静态链表的物理结构是索引存储,而不是链式存储。
我们用两个索引变量 和 分别记录实际链表和空闲链表的头节点的索引,用数组 记录每个节点的数据,用数组 记录每个节点的后继节点的索引。
注意尽量不要用 作为数组名,可能会和STL库发生冲突,因此这里用 代替。
// 定义
const int MAX = ...;
int value[MAX], next[MAX];
int head;
int ehead;
接下来我们简要介绍一下什么是索引存储。
从逻辑本质上来讲,我个人认为链式存储和索引存储是相同的。以链表为例,在链式存储中,我们用 指针指向后继节点的地址,在索引存储中,我们用 记录后继节点在数组中的下标。其实它们是极度相似的,只不过 指针记录的是形如 0x00c42398 , 0x00c4239c 这样的物理地址, 记录的是形如 0 , 1 , 2 这样的逻辑地址(数组下标),只不过后者屏蔽了对底层物理地址的直接访问而已。
我们用 来表示链表为空,用 来表示节点 不存在后继节点。
初始时 ,而 和 要先初始化,形成空闲链表。可以从前往后依次连接,也可以从后往前,或者你开心随便乱连也行,只要能将数组的所有元素连起来即可。
// 初始化
void initialize() {
head = -1;
for (int i = 0; i < MAX-1; i ++) {
nxt[i] = i + 1;
}
nxt[MAX-1] = -1;
ehead = 0;
}
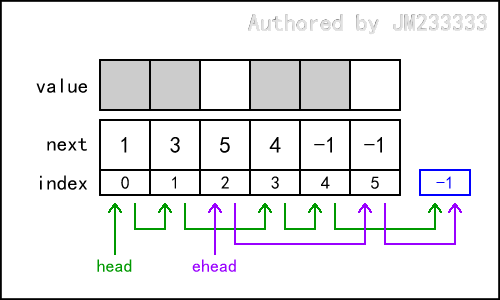
经上述代码初始化后,静态链表的逻辑结构如图所示,其中实际链表为 head -> -1 为空,空闲链表为 ehead -> 0 -> 1 -> 2 -> 3 -> 4 -> 5 -> -1 。
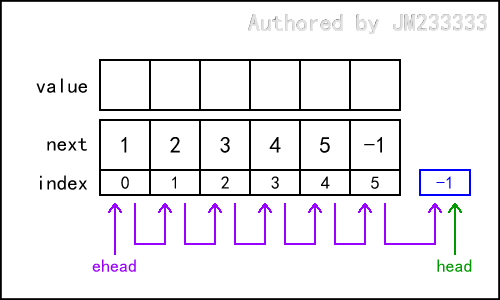
静态链表的逻辑结构如图所示,下面给出两个静态链表的实例。
下图的静态链表中,实际链表为 head -> 0 -> 1 -> 3 -> 4 -> -1 ,空闲链表为 ehead -> 2 -> 5 -> -1 。
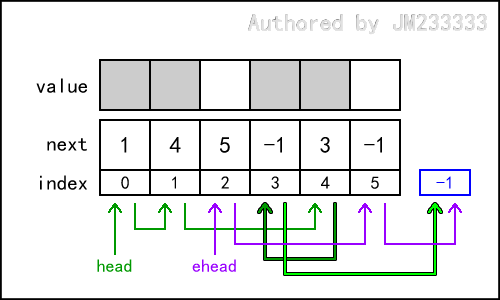
下图的静态链表中,实际链表为 head -> 0 -> 1 -> 4 -> 3 -> -1 ,空闲链表为 ehead -> 2 -> 5 -> -1 。这个链表可能看起来有些奇怪,但经过一些插入删除操作后,它会自然而然地变成这样——例如实际链表的中部被删除了一个节点,随后又在其表头插入了一个节点。这并不重要。
静态链表的操作原理并不难理解。当我们插入时,先从空闲链表中取出(删除)一个节点,就类似于在链表的实现用new开辟了一个节点,然后将该节点插入表中即可。当我们删除时,将对应的节点从表中取出(删除),然后将其插入空闲链表中即可。
因为空闲链表中的每个空闲节点都是逻辑上等价的,所以我们所有对空闲链表的操作都直接在表头进行即可。
下面给出静态链表插入删除的完整代码实现,如果和链表的插入删除的代码进行比较,你会发现它们十分地相似,只是一个用指针一个用索引罢了。
静态链表的代码看起来更复杂一些,也只是因为还要对空闲链表进行操作,多出来的部分也很简单,因为只需要操作空闲链表的表头。相信已经良好掌握链表的你能够比较轻松地理解这些代码。
// 插入
void insert(int p, int val) {
// 从空闲链表的表头取出节点
int q = ehead;
value[q] = val;
ehead = nxt[ehead];
// 插入实际链表的对应位置
if (p == -1) {
nxt[q] = head;
head = q;
} else {
nxt[q] = nxt[p];
nxt[p] = q;
}
}
// 删除
void erase(int p) {
// 从实际链表的对应位置取出节点
int q;
if (p == -1) {
q = head;
head = nxt[head];
} else if (nxt[p] != -1) {
q = nxt[p];
nxt[p] = nxt[nxt[p]];
} else {
// throw an error
}
// 插入空闲链表的表头
nxt[q] = ehead;
ehead = q;
}
下面给出遍历并输出静态链表的代码,也和链表很像。
// 遍历
void traverse() {
printf("head -> ");
for (int i = head; i != -1; i = nxt[i]) {
printf("[%d](%d) -> ", i, val[i]);
}
printf("[-1]()\n");
}
静态链表的一个优点是效率更高,因为动态开辟内存往往是很耗时间的,静态链表可以静态分配内存,速度更快,但又能继续持有链表的基本特性。但这不是它最重要的优点。
静态链表的最重要的优点是,在一定程度上弥补了链表在表内操作的困难。
我们知道,如果想 地进行表内插入或删除,我们必须预先拥有对应节点的指针,这使得我们通常只会在一次遍历的过程中进行频繁的表内插入或删除,否则链表的效率并不好。
而现在,我们可以像访问数组元素一样访问链表中的任何节点——问题在于,我们无从得知这是链表中从表头起的第几个节点,也无从得知该节点是否属于实际链表(它可能属于空闲链表)。前者是无法解决的,后者可以通过开辟一个额外的布尔数组来解决,用 表示节点 是否属于实际链表,在插入和删除时维护该数组即可。
当然,静态链表的缺点也很明显,它在继承了链表优点的同时也继承了链表的所有缺点,此外由于是静态分配空间,它也继承了顺序表的一大缺点——必须能够预知表长的上界。
即便如此,因为静态链表很好地支持了表内插入或删除,哪怕不那么完美(无法确定这是从表头起的第几个节点),它也在许多场合得到了广泛的应用,例如我们可以用它进行静态建树,或是实现图的链式前向星存储等。
下面给出链表与静态链表的对比,可以看到,二者仅是物理结构不同,而且链式存储和索引存储本身就非常相似。
| 数据结构名称 | 逻辑结构 | 物理结构 | 额外空间复杂度 |
|---|---|---|---|
| 链表 | 线性结构 | 链式存储 | |
| 静态链表 | 线性结构 | 索引存储 |
# 链表的应用
至于链表的应用,除了很多公司的面试题和笔试题中会出现以外,在实际中,它是许多数据结构和系统的底层支持,例如哈希冲突的解决、图的链式前向星存储、操作系统中的文件系统等,此处不予赘述。
# 顺序表与链表
下面给出顺序表与链表的部分基本操作的时间复杂度的对比。
| 操作 | 顺序表 | 链表 |
|---|---|---|
| 随机查找和修改 | ||
| 随机插入和删除 | 查找耗时 | |
| 在表头处插入和删除 | ||
| 在表尾处插入和删除 | ,若额外维护表尾指针则为 | |
| 额外空间复杂度 |
- 01
- Reading Papers - Kernel Concurrency06-01
- 02
- Linux Kernel - Source Code Overview05-01
- 03
- Linux Kernel - Per-CPU Storage05-01