 Data Structure 02 - Restricted Linear List
Data Structure 02 - Restricted Linear List

# 前置知识
在阅读本文档前,请确保你已经掌握线性表的基础知识,详见 Data Structure 知识板块中的 01 - Linear List 文档。
# 基本概念
从功能受限的角度上,除了非受限线性表以外,我们可以将线性表分为栈和队列两大类。
受限线性表 (restricted linear list) 指的是部分功能受限的线性表,即我们禁止该线性表进行某些基本操作,例如禁止随机查找和修改,或是禁止在表尾处插入等。
或许你会对此感到困惑,为什么好好的功能要禁止?这是因为在很多情况下我们不需要其他的功能,或是随意使用某些功能会导致程序混乱或错误,或是对保留下来的这些功能更加关注,那么使用受限线性表可以帮助我们集中精力去关注这些有用的功能,并且也非常有利于展示自己的思想——比如你说你在这段程序里用到的是栈,就能很清晰地告诉别人你大概希望做些什么,但如果你不使用受限线性表,你就不得不花费额外的精力去解释。
例如你在维护一个排队服务系统,如果你允许随机插入,这意味着你允许插队行为,这显然是不合理的。
也就是说,受限的意义更多地是在语义上的作用,和我们的实际需求有关。如果你用非受限线性表来代替所有的受限线性表,从底层实现上来说是没有任何问题的,但却可能留下语义上的不妥当,乃至留下将来出错的隐患。
因此,受限线性表可能在初学者看来非常无厘头,但它们在计算机领域却是至关重要的,甚至可以说在某些方面比非受限线性表还要应用地更加广泛,将来学得多了你就明白了。
另外,受限线性表的概念仅针对逻辑上对功能的限制,其底层可以是顺序表、可以是链表,或许其中某一种更合适,又或者无所谓,这两类概念之间没有必然的联系。
因为用顺序表(即数组)来实现栈的代码比较简洁,更适合用来表达栈的思想,所以我们的代码示例均为数组实现。你当然也可以使用链表,这更加灵活,在有些场合比数组实现要好得多。
# 栈
# 概念
栈 (stack) 是一种最基础的受限线性表,它将表的内部封装起来,仅将表的一端供给外界进行修改,我们称这一端为栈顶。
栈的结构如图所示,通常我们用一个 变量维护当前栈顶的位置,或是维护当前栈顶的后继位置。这是两种不同的内部实现方式,但它们在逻辑上是等价的。
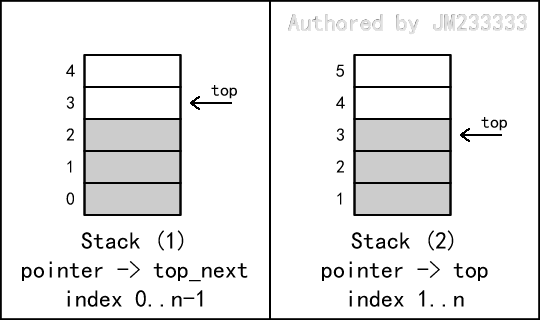
# 定义
我们的代码示例用 维护当前栈顶的后继位置,下标从 起。对此的扩展解释详见下文中的“栈的深入理解”一小节。
// 定义
const int MAX = ...;
int stk[MAX];
int top = 0;
# 基本操作
栈仅允许如下基本操作:
入栈:将元素压入栈顶。
出栈:弹出栈顶元素。
查询栈顶元素。
查询栈中元素个数,以及判断栈是否为空或为满。
栈的核心特征是 先进后出 (last in first out, LIFO) 。因为在出栈时,只有栈中最后入栈的元素可以被最先弹出。
入栈和出栈的操作如图所示。
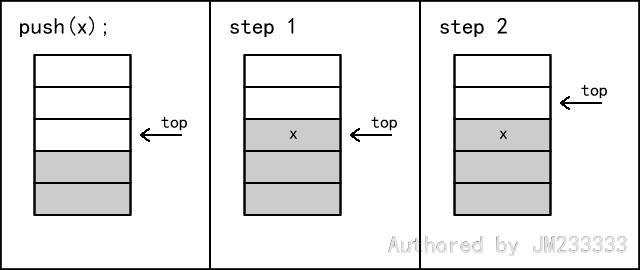
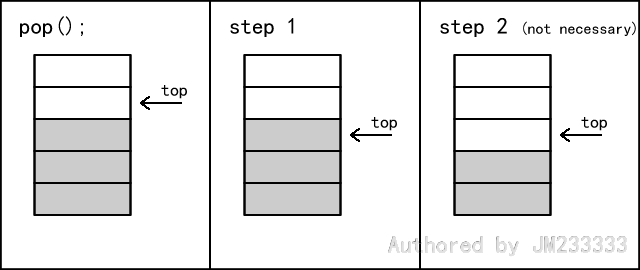
注意,在实际实现出栈时,我们不需要把对应元素清零,因为下一次入栈时会将该块数据直接覆盖,以至于以前的数据不会有任何影响,这也是懒惰删除的一种。
栈的核心代码其实非常简单,可以说是一目了然。不要一上来就去啃那些封装类,那会使你的注意力分散到类的实现上,而不能集中于栈的思想本身。
事实上,栈就是这么简单。我想,配合上面的图示,这些代码是很好理解的,我就不一一赘述了。
// 入栈
void push(int value) {
stk[top] = value;
top ++;
}
// 出栈
void pop() {
top --;
}
// 查询栈顶
int get_top() {
return stk[top-1];
}
// 查询栈中元素个数
inline int size() {
return top;
}
有些地方的代码实现会让返回被弹出的元素,这无所谓,看个人喜好即可。
// 出栈:另一种风格
int pop() {
int x = stk[top];
top --;
return x;
}
当然,别忘了我们需要判断栈是否为空,并在出栈和查询栈顶时判断。此外,因为我们是用数组实现的栈,所以我们还需要判断栈是否为满,并在入栈时判断。
// 入栈
void push(int value) {
if (full()) {
// throw an error
}
stk[top] = value;
top ++;
}
// 出栈
void pop() {
if (empty()) {
// throw an error
}
top --;
}
// 查询栈顶
int get_top() {
if (empty()) {
// throw an error
}
return stk[top-1];
}
// 查询栈中元素个数
inline int size() {
return top;
}
// 判断栈是否为空
inline bool empty() {
return (top == 0);
}
// 判断栈是否为满
inline bool full() {
return (top == MAX);
}
# 栈的深入理解
前文已经提到过,“受限线性表”的概念和“顺序表与链表”的概念之间没有必然的联系。下面我们详细解释一下来帮助读者认识到这一点。
如果栈的实现是顺序表,则栈顶习惯上为表尾。当然,也可以是表头,如果你非要倒着使用数组的话,这无所谓。
如果栈的实现是链表,则栈顶习惯上为表头。毕竟 指针指向的是表头。当然,也可以是表尾,如果你非要另外用一个指针维护表尾的话。
也就是说,我们不应该去过分关注这些和栈本身的概念无关的事情,底层如何实现完全是你的自由,应当取决于实际情况。
用顺序表或链表来实现栈的优缺点都很明显。
顺序表的实现代码简洁明了,一个数组和一个栈顶索引变量即可解决,不像链表还要定义一个节点类并写出相对复杂的插入删除代码。但你必须要预知栈的大小。
而链表的实现代码虽然复杂一些,但它非常灵活,在无法预知栈的大小的上界时,我们通常会使用链表实现。
同样地,你可以令下标从 起或是从 起,那么根据 的定义的不同,你对 的初始化也会不同。
用 维护栈顶后继,下标从 起,则初始化 。
用 维护当前栈顶,下标从 起,则初始化 。
用 维护栈顶后继,下标从 起,则初始化 。
用 维护当前栈顶,下标从 起,则初始化 。
这些在逻辑上都是等价的,只是内部实现不同而已。之所以在这里耗费这么大篇幅去解释这一无关紧要的事实,是因为有些初学者会掉入误区,误以为栈只能怎么怎么样去实现。
习惯上我们会使用 1 和 2 。上文中的代码示例使用了 1 的实现,下面给出了 2 的实现。
// 定义
const int MAX = ...;
int stk[MAX];
int top = 0;
// 入栈
void push(int value) {
if (full()) {
// throw an error
}
top ++;
stk[top] = value;
}
// 出栈
void pop() {
if (empty()) {
// throw an error
}
top --;
}
// 查询栈顶
int get_top() {
if (empty()) {
// throw an error
}
return stk[top];
}
// 查询栈中元素个数
inline int size() {
return top;
}
// 判断栈是否为空
inline bool empty() {
return (top == 0);
}
// 判断栈是否为满
inline bool full() {
return (top == MAX-1);
}
读者可以和1.的实现对比加深理解,事实上,它们在逻辑上是等价的。
不过需要注意的是,如果你需要应付课内的考试,那么请你以你的课本中所使用的实现方式为准。
# 栈的扩展
栈的高级扩展还有单调栈,因为这已经超出了本文的难度,故此处不予赘述,详见 Data Structure 知识板块中的 DS xx - xx 文档。
# 栈的应用
不要忘了,数据结构只是我们解决问题的工具。这里我只会列出一些最简单和最基础的应用,这是栈的高级应用的根基所在。
# 序列反转
栈的基本特性是 LIFO ,这意味着我们可以利用栈把一个序列逆序输出。
比如将整数转换为字符串,或是十进制转二进制,我们只能从低位到高位处理数字,按照这个顺序输出肯定是不对的,这时我们可以将每个处理出来的数位依次入栈,最后再全部出栈,即可调整到从高位到低位的正确输出顺序。
当然,我们也可以用 reverse 解决,但这有时候不那么方便,如果使用一个封装好的栈通常会使得代码更简洁,效率有时候也更高。
下面给出将整数转换为字符串的代码实现。
void itos(int x) {
stack<int> s;
while (x > 0) {
s.push(x % 10);
x /= 10;
}
while (!s.empty()) {
output(s.top());
s.pop();
}
}
# 括号匹配
问题:给定一个字符串,串中仅包含(和)两种字符,判断串中的括号是否两两匹配。例如()和(())()是匹配的,而((和)(()不是。
这是一个经典的用栈解决的问题。
我们依次遍历串中的每个字符,如果遇到左括号,则将其入栈;如果遇到右括号,则将栈顶的左括号出栈,如果栈为空,说明右括号出现多余,串是不匹配的。在遍历完成后,如果栈为空则说明串是匹配的,否则串是不匹配的。
下面给出代码实现。
bool match(const string & str) {
stack<char> s;
for (int i = 0; i < str.length(); i ++) {
if (str[i] == '(') {
s.push(str[i]);
}
if (str[i] == ')') {
if (s.empty()) {
return false;
} else {
s.pop();
}
}
}
return (s.empty());
}
问题可以拓展为多种括号,如串中包含(, ), [, ]四种字符,不允许形如([)]的匹配。这些问题的核心原理都是类似的,此处不予赘述。
# 解决算术表达式问题
后缀表达式的求解,以及将中缀表达式转换为后缀表达式。
(unfinished)
# 递归的本质
(unfinished)
# 单调栈的应用
(unfinished)
# 队列
# 概念
队列 (Queue) 是一种最基础的受限线性表,它将表的内部封装起来,仅允许在表的一端进行插入、在表的另一端进行删除或访问,我们称允许删除和访问的一端为队首,称允许插入的一端为队尾。
队列的结构如图所示,通常我们用两个变量 和 维护队首和队尾,类似于栈,我们既可以用 维护队尾的本身,也可以维护队尾的后继,它们在逻辑上是等价的。此外,虽然我们也可以用 去维护队首的前继,但这会带来一些麻烦,因此我们习惯上通常不会这么做。
有时也会用 和 代替 和 表示队尾和队首,这只是个名字,不要在意。
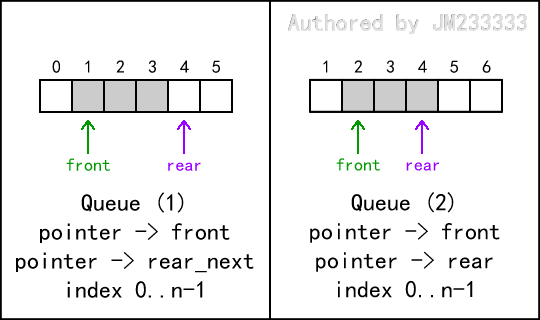
# 定义
我们的代码示例中,用 维护队首,用 维护队尾的后继,下标从 起。对此的扩展解释详见下文中的“队列的深入理解”一小节。
const int MAX = ...;
int q[MAX];
int front = 0, rear = 0;
# 基本操作
队列仅允许如下基本操作:
入队:将元素压入队尾。
出队:弹出队首元素。
查询队首元素。
查询队列中元素个数,以及判断队列是否为空或为满。
队列的核心特征是 先进先出(first in first out, FIFO) 。和栈不同,队列的结构决定了队中元素的出队顺序和入队顺序是一致的。
入队和出队的操作如图所示。
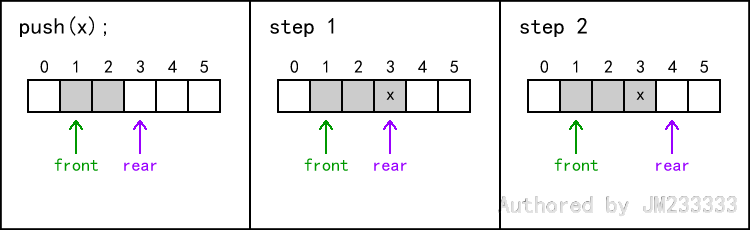
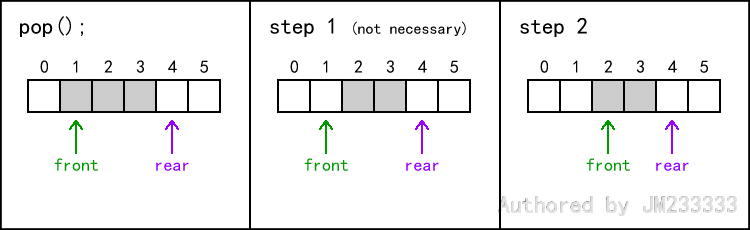
注意,在实际实现出队时,我们不需要把对应元素清零,理由同实现出栈,进行懒惰删除即可。
队列的核心代码同样非常简单。类似于栈,我们也需要针对队列为空或为满的情况对出队和入队操作进行修正。因为在栈的部分已经有过省略这些排错代码,相信读者已经能够很好地理解,所以这里就不再省略了,直接给出完整的代码。
// 入队
void push(int value) {
if (full()) {
// throw an error
}
q[rear] = value;
rear ++;
}
// 出队
void pop() {
if (empty()) {
// throw an error
}
front ++;
}
// 查询队首
int get_front() {
if (empty()) {
// throw an error
}
return q[front];
}
// 查询队列中元素个数
inline int size() {
return (rear - front);
}
// 判断队列是否为空
inline bool empty() {
return (front == rear);
}
// 判断队列是否为满
inline bool full() {
return (rear == MAX);
}
需要注意的是队列的判满。细心的读者可以发现,我们不能像栈那样进行形如下列代码的判定:
// 判断队列是否为满(错误)
inline bool full() {
return (size() == MAX);
}
因为栈是单向进出的,栈底从来不会移动,而队列是一向进一向出,队尾和队首都在不断地前进。
所以,我们在预估队列数组的大小时,需以入队次数为标准,而非以队中最大保持元素个数为标准。
此外,这还意味着可能出现下图中所示的情况。
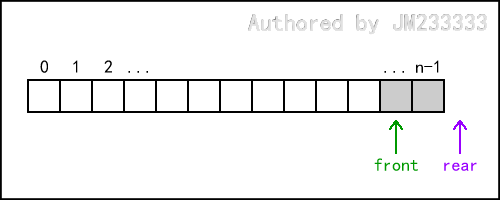
我们称这类情况为队列的假溢出(仅针对数组实现的队列),即虽然数组中空间尚未用尽,但是我们却不得不认为队列已满。上图的情况已经是最严重的情况之一,可以看到空间被大量地浪费。
针对这一问题的解决方案有两个。
其一是使用链表来实现队列,显然在链表实现下我们不需要担心这种问题,因为空间总是动态开辟和销毁的。
其二是使用数组实现的循环队列,详见下文中的“队列的扩展”一小节。
# 队列的深入理解
类似于栈,我们也有不同的方法来实现队列。
用 维护队首,用 维护队尾的后继,下标从 起,则初始化 。
用 维护队首,用 维护队尾,下标从 起,则初始化 。
上文中的代码示例使用了1.的实现,下面给出了2.的实现。
// 入队
void push(int value) {
if (full()) {
// throw an error
}
rear ++;
q[rear] = value;
}
// 出队
void pop() {
if (empty()) {
// throw an error
}
front ++;
}
// 查询队首
int get_front() {
if (empty()) {
// throw an error
}
return q[front];
}
// 查询队列中元素个数
inline int size() {
return (rear - front + 1);
}
// 判断队列是否为空
inline bool empty() {
return (front > rear);
}
// 判断队列是否为满
inline bool full() {
return (rear == MAX-1);
}
# 队列的扩展
# 循环队列
上文提到过,为了避免数组实现的队列发生假溢出,我们经常使用循环队列。
循环队列 (circular queue) 的限制条件和队列一样,但它允许队首和队尾在到达数组末端后返回数组首端。
下面我们仍然用 维护队首,用 维护队尾的后继,下标从 起。
循环队列的原理很简单,如下图所示,在逻辑上,我们将数组首尾相接,这样一来,当 到达数组末端时,若继续 ,且数组首端并未被占用(即发生假溢出),则 会折回首端,继续利用剩余的空间。类似地, 也会如此。
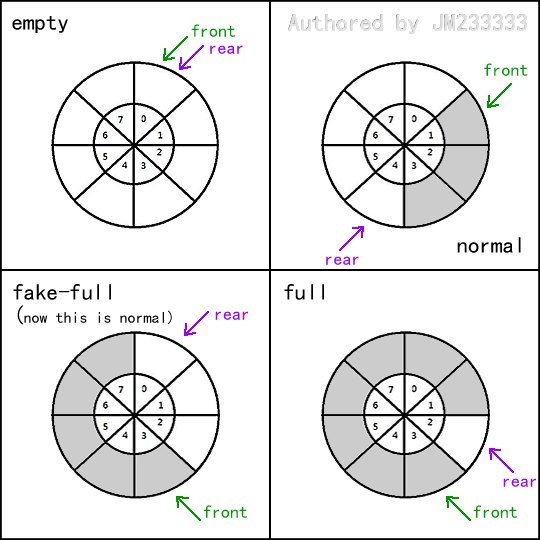
需要注意的是循环队列的判满。
我们不能把整个数组完全填满,那样会导致 ,那么我们将无从得知队列是空还是满。所以我们必须留出一个空位。尽管如此,只浪费 的空间已经是无关紧要的了。
事实上,这个问题也是可以解决的。我们另外用一个计数器 ,表示当前队中元素个数,在出队和入队时维护 的值,那么当 时,根据 是否为 即可判断队列是空还是满。
下面考虑如何用代码来实现。考虑到代码的简洁,我们使用第一种判空判满的风格,浪费一个单位的空间。
在实际实现上,我们不需要真的把数组首尾相接,只需要令 和 对 取模即可。
// 入队
void push(int value) {
if (full()) {
// throw an error
}
q[rear] = value;
rear = (rear + 1) % MAX;
}
// 出队
void pop() {
if (empty()) {
// throw an error
}
front = (front + 1) % MAX;
}
// 查询队首
int get_front() {
if (empty()) {
// throw an error
}
return q[front];
}
需要注意的是,查询队列中元素个数没有那么简单,直接把 和 相减肯定是不对的。
当 时,元素个数为 。
当 时,元素个数为 ,即 。
可以精炼得到公式 ,但是你要知道这个公式是怎么来的,本质上只是对前面的分类讨论的一个精炼。
如果感到难以理解,可以结合上文中的图示来看。
// 查询队列中元素个数
inline int size() {
return ((rear - front + MAX) % MAX);
}
// 判断队列是否为空
inline bool empty() {
return (front == rear);
}
// 判断队列是否为满
inline bool full() {
return (front == (rear + 1) % MAX);
}
# 双端队列
有些时候,我们希望在线性表的首尾两端均可插入和删除,这种数据结构称为双端队列,它的限制程度比队列要低。
双端队列 (double-ended queue) 是指允许两端都可以进行入队和出队操作的队列。
在理解了队列以后,双端队列应该并不难理解,不过构建一个循环双端队列比较麻烦,因此我们通常还是会用链表实现,常用双向链表作为双端队列的底层。
因为原理很简单,故此处不再赘述代码实现。
需要注意的是, STL 中的 deque 虽然冠以双端队列之名,但它是允许随机访问的,为此其内部实现也并非链表,而是一种较为复杂的结构。所以严格意义上来说它和这里所述的双端队列是两回事,还望区分。
此外,队列的高级扩展还有单调队列,因为这已经超出了本文的难度,故此处不予赘述,详见 Data Structure 知识板块中的 DS xx - xx 文档。
# 队列的应用
- 模拟排队过程。
队列的基本特性是 FIFO 。在很多模拟系统中都有排队的过程,排队显然是先进先出的,这时我们就可以使用队列来解决问题。
BFS的实现。
双端队列和单调队列的应用。
# 串
串 (string) 也是一种最基础的受限线性表,即字符串,
相对于栈和队列而言,我们很少提及串,因为我们通常把串当作字符串对待,而不是当作数据结构对待,对串的研究通常更倾向于字符串理论方面。此外也是因为串的受限情况非常简单,因而此处也只做简单介绍,更多关于串的知识请参考 String 知识板块。
- 01
- Reading Papers - Kernel Concurrency06-01
- 02
- Linux Kernel - Source Code Overview05-01
- 03
- Linux Kernel - Per-CPU Storage05-01