
C Programming Language
Basics #02: Function
# Basic Tutorial, # Programming Language, # C Programming LanguageLast Updated: 2020-01-01
前置知识
在阅读本文档前,请确保你已经掌握指针的基础知识,详见 Basics #01: Pointer 。
前言
函数 (function) 是绝大多数编程语言中都存在的概念,有时它被称为 方法 (method) ,但在 C/C++ 语言中我们习惯使用“函数”来称呼它。
我不打算再花费多少篇幅来介绍函数是什么,因为我已经提到过我会假设读者同时在通过其他途径学习 C 语言,这种简单的概念的教程实在是太多了。我主要会介绍和函数相关的各种易错点和重难点知识,还会详细介绍如何正确地使用函数——这是许多初学者自己花费很长时间都学不明白的事情。
函数的声明和定义
我不打算在这种过于简单的知识点上浪费太多笔墨,我只给出一些较为精简的描述和对比。
基本概念:
-
函数声明告诉编译器函数需要使用的参数数量、参数的数据类型和函数的返回值类型。在调用函数前必须先给出对应的函数声明。
-
函数定义告诉编译器函数具体的执行代码。函数定义可以放在程序的任何位置,只要调用该函数的代码能找到它。
二者差异:
-
函数声明可以有多个,但函数定义只能有一个。
-
函数定义本身就包含了函数声明。也就是说,如果把函数定义放在所有调用该函数的代码的前面,也是完全合法的。
-
在函数声明中指定参数的名称是可选的,但是没有实际作用,而函数定义中必须指定参数的名称,且发挥实际作用。
下面的代码是完全合法的,供读者参考:
int add(int, int);
int add(int a, int b);
int add(int a, int);
int add(int, int b);
int mul(int s, int t) {
int prod = s * t;
return prod;
}
int main(void) {
int x = 1, y = 2;
int res1 = add(x, y);
int res2 = mul(x, y);
return 0;
}
int add(int x, int y) {
int sum = x + y;
return sum;
}注意事项:
-
即便实际上没有作用,我们仍然会经常在函数声明中指定参数的名称,且与定义中指定的名称保持一致。这是一个良好的习惯,其主要目的是让编程者能够了解每个参数的含义,方便对其进行调用。否则如果函数参数过多,则看到函数声明的人会面对一大堆无名参数陷入困惑,不得不去寻找函数的具体定义。当然,如果是非常简单的函数,或是在配套文档中有对函数接口的详细解释,那么在声明时将参数名称省略也未为不可。
-
在调用函数前必须先给出对应的函数声明,但是如果没有给出函数声明,在有些情况下编译器不会报告错误,初学者需要小心。下文中会给出对此类风险的详细介绍。
函数的参数传递
实参和形参
实参和形参是函数参数传递的基本概念:
-
在函数调用时被作为参数传递给函数的表达式称为 实际参数 (arguments, or actual arguments) ,简称为 实参 。
-
在函数定义中被定义的参数变量称为 形式参数 (parameters, or formal parameters) ,简称为 形参 。
以下面这段简单的代码为例:
int add(int x, int y) {
int sum = x + y;
return sum;
}
int main(void) {
int a = 1, b = 2;
int res = add(a, b);
return 0;
}在 main 函数中调用函数 add(a, b) 时,变量 和 作为实参被传递给 add 函数;而在 add 函数中定义的两个参数 和 作为形参接收来自实参的值,在此处相当于令 , 。
实参可能有很多组,因为每次调用函数都可能使用不同的表达式作为实参传递给函数;而形参只有一组,它们在函数定义中会被明确指定唯一的标识符名称。例如:
int add(int x, int y) {
int sum = x + y;
return sum;
}
int main(void) {
int a = 1, b = 2;
int res1 = add(a, b);
int res2 = add(a + b, 2 * a);
int res3 = add(5, a - b);
return 0;
}可见无论如何 add 函数的形参总是 和 ,而实参在不同的函数调用中可能是不同的表达式。对于函数内部的代码而言,实参是什么以及实参有多少种都不重要,因为对它来说只有形参是有意义的。
值传递和引用传递
对于未曾接触过其它编程语言的初学者来说,这两个概念可能有些不太好理解。但是假如你阅读了我介绍指针的文章,那么你应该对内存、地址和指针的概念都已有所了解,这个问题就变得很简单了。
-
如果函数传参使用 值传递 (pass by value) 的方式,那么每个实参的值会被复制到对应的形参上,实参和形参变量使用不同的地址。
-
如果函数传参使用 引用传递 (pass by reference) 的方式,那么每一组对应的实参和形参将表示相同的内存地址,二者相当于同一个变量的不同名称。
考虑如下的简单代码示例:
#include <stdio.h>
void inc(int x) {
x ++;
}
int main(void) {
int a = 1;
inc(a);
printf("%d\n", a);
return 0;
}对应于上述代码的 inc 函数,值传递和引用传递的示意图如下所示:
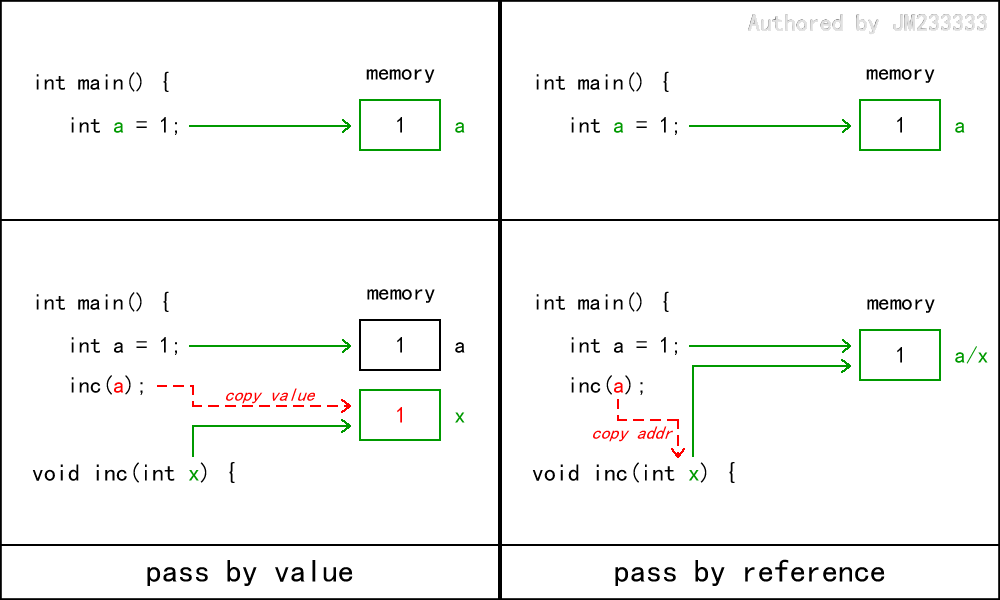
注意图中的绿色实线箭头表示的是从变量名到内存地址的映射。
如果 C 语言的函数传参是值传递的,那么输出的结果为 1 ,因为在函数中对局部变量 的操作和主函数中的变量 没有任何关系,二者是完全不同的变量——即便它们的名字可能相同,那也只是巧合罢了。
如果 C 语言的函数传参是引用传递的,那么输出的结果为 2 ,因为变量 和 表示的是相同的内存地址,对 修改和对 修改是完全等价的——即便它们的名字可能不同,那也是同一个变量的两个名字。
上述代码的运行结果如下:
1由此可见, C 语言的函数传参是值传递的。那么如果我们想在函数中对传入的实参进行修改应该怎么办?只能使用全局变量吗?答案是使用指针,下一小节将对此进行介绍。
使用指针作为函数参数
因为 C 语言的函数传参是值传递的,所以为了在函数中对外部的变量进行修改,我们需要使用间接访问的方式——将外部变量的地址作为参数传递到函数中。这样一来,即便形参只是一个副本,只要地址值是相同的,我们就能通过该地址值找到同样的内存位置,对外部的变量进行修改。
先以前文所述的 inc 函数为例,要想实现对某个变量 的功能,我们只需要把函数定义及其调用修改为如下代码即可:
#include <stdio.h>
void inc(int * p) {
(*p) ++; // or *p += 1 , *p = *p + 1
}
int main(void) {
int a = 1;
inc(&a);
printf("%d\n", a);
return 0;
}或者这样写也是一样的:
#include <stdio.h>
void inc(int * p) {
(*p) ++; // or *p += 1 , *p = *p + 1
}
int main(void) {
int a = 1;
int * p = &a;
inc(p);
printf("%d\n", a);
return 0;
}注意 inc 函数中的 (*p) ++ 不能略写成 *p ++ ,这在我介绍指针的文章中已经提到过,根据运算符优先级,这会被解读为取 *p 然后令 p ++ ,不符合我们在此处的需求。
上述代码的函数传参的示意图如下所示:
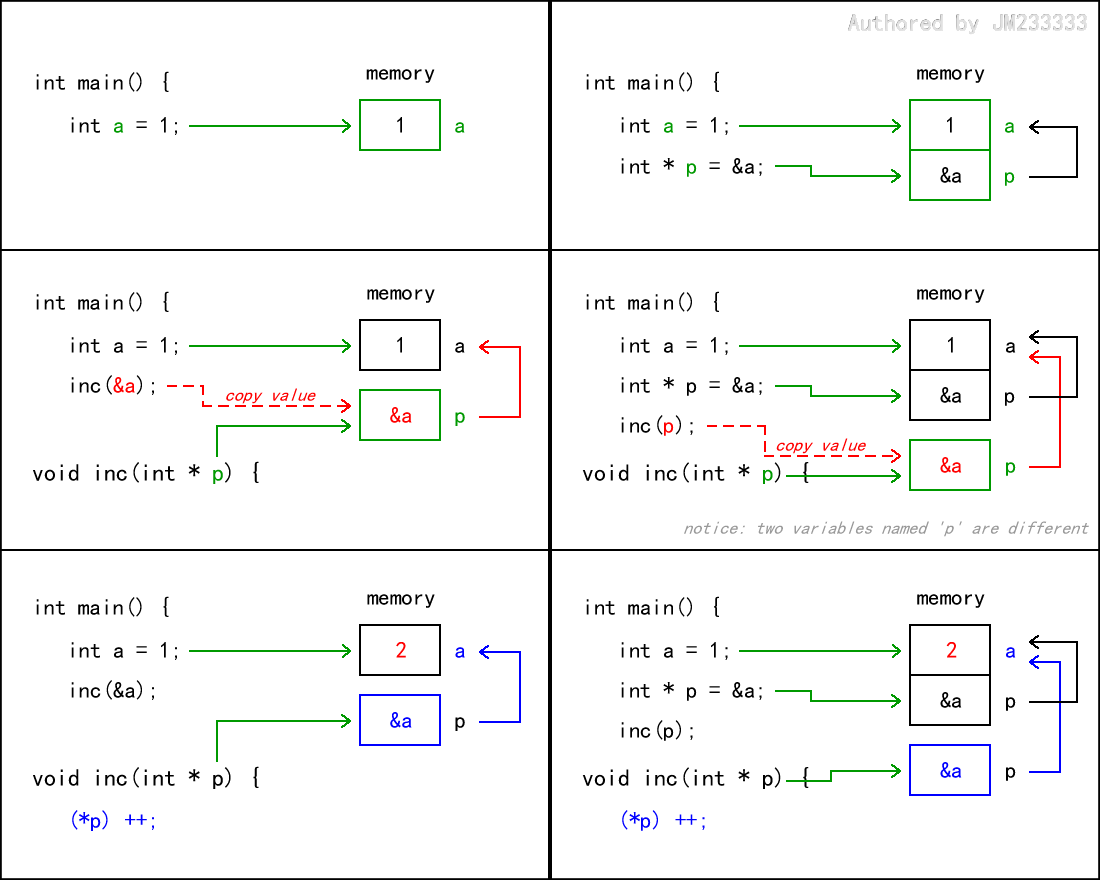
上述代码的运行结果如下:
2再以最常见的例子 swap 函数为例,我们希望用 swap 函数交换两个变量的值。由于值传递的特性,下面的代码无法满足我们的要求,它只会交换两个副本变量的值,和主函数中调用 swap 函数时传入的实参 和 没有一点关系:
void swap(int a, int b) {
int t = a;
a = b;
b = t;
}
int main(void) {
int a = 1, b = 2;
swap(a, b);
printf("a = %d, b = %d\n", a, b);
return 0;
}上述代码的运行结果如下:
1 2但是我们借助指针就可以彻底解决这个问题。即便形参是外部变量的地址的副本,但是地址值是相同的,我们就能对地址解引用并对其值进行交换:
void swap(int * a, int * b) {
int t = *a;
*a = *b;
*b = t;
}
int main(void) {
int a = 1, b = 2;
swap(&a, &b);
printf("a = %d, b = %d\n", a, b);
return 0;
}上述代码的运行结果如下:
2 1那么如果我们希望实现一个 swap_ptr 函数交换两个指针的指向呢?此时我们应该使用指向指针的指针作为函数参数,因为现在我们要间接访问指针变量:
void swap_ptr(int ** a, int ** b) {
int * t = *a;
*a = *b;
*b = t;
}注意,指针的函数传参是初学者极易出错的地方,请特别关注如何在函数中修改指针的指向,并确保自己理解其中的所有原理。
在 C 语言的 02 - Pointers 文档中我提到过, 指针变量只是一种被赋予了特殊语义的变量,它的内容本质上就是一个无符号整数, 不要忘记这一点。当我们通过指针去间接访问并修改一个普通变量的值的时候,事实上并没有修改指针本身。而如果我们想修改指针本身,则必须通过二级指针来修改,否则你只是在修改一个副本罢了。
在下面的代码中,两个 并不是同一个变量,所以修改函数中的形参 是不会影响到你传入的实参 的,这和你无法直接通过 swap 去交换两个普通整数变量的原因是一致的。
void f(int * p) {
p ++; // useless
}
int main(void) {
int a[5];
int * p = &a[0];
f(p);
}数组与函数传参
为了避免使用大量的全局数组,我们经常需要将数组作为参数传递,例如:
void output(int a[], int n) {
int i;
for (i = 0; i < n; i ++) {
printf("%d%c", a[i], (i == n - 1 ? '\n' : ' '));
}
}但是这里有一个初学者极易弄错的问题。
当你把数组作为参数传递时,事实上传递的是一个指向数组首地址的指针,而非数组名本身。即便你在函数的形参列表中写的是数组类型,它也会被视为一个指针。也就是说,下面两种语法是完全等价的:
void f(int a[], int n);
void f(int * a, int n);在第一种语法中,声明数组的长度是合法的,但这并不会起到任何作用,传递给函数的仍然只是一个指针,和上面两种语法是完全等价的:
void f(int a[100], int n);因此,虽然在函数体中我们既可以使用数组的语法也可以使用指针的语法,但是实际上我们都是在对一个指针进行操作。这也是当我们将数组作为参数传递时,需要另外传递一个整数参数来记录数组长度,而不能利用 sizeof 来获取数组长度的原因:
void f1(int a[], int n) { // correct
// ...
}
void f2(int a[]) {
int n = sizeof(a) / sizeof(int); // wrong
// ...
}考虑到语义的清晰性,我们通常鼓励使用第一种语法,因为这能明确告诉程序员,这里期望接收的是一个数组的首地址,而不是单个变量的地址。因为我们完全有可能定义某个函数,他的参数是一个指向整型的指针和一个整型:
void f(int * p, int n) {
*p = n * n - *p;
}至于将二维数组作为参数传递时,事实上是退化成了数组指针,下面两种函数声明是等价的:
void f1(int a[][10], int n);
void f2(int (*a)[10], int n);而更高维的数组则会退化为对应的高维的数组指针,读者可以自行推演。
数组名和指针是不同的。初学者无需深入地探究它们之间的区别,但绝不能认为数组名是个指针。关于数组名和指针的区别的更多具体信息,详见 C 语言的 05 - Array Name is NOT a Pointer 文档。
函数声明的陷阱
C 语言对函数声明的语法规定非常宽松,因此一些初学者会因为自己的失误而陷入难以发现的 BUG 中不能自拔。
正确声明无参函数
很多人并不知道,下面两种函数声明是不同的,即便它们可以共存:
void f();
void f(void);这是 C 语言一直保持着的一个语法特性——虽然这个特性令我感到十分迷惑,我实在是不明白为什么要允许这种毫无意义的语法特性存在。事实上 C++ 也将这一特性摈弃了。
在 C++ 语言中,这两种函数声明是等价的,它们均表示一个没有参数的函数。但是在 C 语言中,当我们希望声明一个没有参数的函数时,应当使用第二种方式来声明函数。当你使用第一种方式时,事情并不会像你想象的那样。考虑下面的代码:
void f() {
;
}
int main(void) {
int x = 1, y = 2, z = 3;
f();
f(x);
f(x, y, z);
f(x, x);
return 0;
}你一定会觉得这段代码看起来很荒唐,然而事实上这段代码可以在任何标准 C 环境下编译通过——虽然一些并不绝对严格遵循标准的编译环境可能会对此发出警告。
在 C 语言中,空的参数列表的含义是“可以使用任意多的参数”,而不是“没有参数”。如果你使用这种语法,你的函数会有潜在的被误用的风险,除非你真的想接收任意多的参数,否则你都应该写成:
void f(void) {
;
}
int main(void) {
int x = 1, y = 2, z = 3;
f();
f(x);
f(x, y, z);
f(x, x);
return 0;
}上述代码的第 行均会报告编译错误。
不过现在你很可能会有另一个疑惑——如果真的想接收任意多的参数,使用这种语法特性,可是参数列表是空的,在函数中如何获取这些被传入的参数呢?
空的参数列表当然没有办法,但是下一节给出了一个利用该语法特性的方法,虽然它已经在 C99 标准中被废除。
隐式 int 声明
在 C89 标准中还有另一个语法特性:在函数声明中,函数参数和返回值的类型说明符可以被省略,此时将默认为 int 类型。例如下面的代码在 C89 标准中是合法的:
f1(int x) {
return (x + 1);
}
int f2(x) {
return (x * 2);
}
f3(x) {
return (x * 3 + 5);
}
int main(void) {
int x = 1;
int y = f1(x);
int z = f2(x) + f3(x);
return 0;
}我暂未找到这一特性的官方名称,但它有时被俗称为隐式 int 声明。
结合隐式 int 声明的特性,我们就可以利用空的参数列表来让函数接收任意多的参数了,缺少的参数将被置为 0 ,多余的参数则无法被获取:
#include <stdio.h>
void f(a, b, c) {
printf("%d %d %d\n", a, b, c);
}
int main(void) {
int x = 1, y = 2, z = 3;
f();
f(x);
f(x, y, z);
f(x, x);
return 0;
}上述代码的运行结果如下:
0 0 0
1 0 0
1 2 3
1 1 0然而隐式 int 声明已经在 C99 标准中被明文规定彻底废弃,如果使用严格的 C99 标准,缺少类型说明符的函数声明会报告编译错误。
这也就是我说空的参数列表的语法特性毫无意义的原因——从 C99 开始你根本无法运用这种语法特性,因为当隐式 int 声明的特性被废除后,我们就无法通过常规语法层次的手段在函数中获取这些被传入的参数。这一语法特性存在的唯一“价值”就是给一些对此并不知情的编程者造成困扰,除此以外没有任何意义。
综上所述,当你希望声明一个没有参数的函数时,应当使用 (void) 而不是 () ,并且不推荐以任何形式利用空的参数列表和隐式 int 声明这两种分别是毫无意义和废弃的语法特性。
另外,我们也建议不要利用隐式 int 声明来省略函数返回值的类型说明符,例如:
f(int x, double y) {
return x + (int)y;
}一方面是因为 C99 已经将该特性废弃,另一方面也正是该特性被废弃的理由——相比于省略区区三个字母,预防类型说明符的无意遗漏更为重要。万一你不是想返回 int 类型,而只是不小心写漏了呢?
隐式函数声明
你一定知道,函数必须先声明再调用,至于函数的定义则可以放在任意的位置:
int add(int, int);
int main(void) {
int x = 1, y = 2;
int res = add(x, y);
return 0;
}
int add(int x, int y) {
int sum = x + y;
return sum;
}类似于隐式 int 声明,在 C89 标准中,缺失声明的函数调用会默认生成如下的函数声明,称为隐式函数声明:
int add();隐式函数声明只会使用 int 类型的返回值和空的参数列表。前文已经提到过,这意味着我们可以在调用该函数时使用任意多的参数,因此下面的代码可以编译通过,而且从外表上看起来没有任何问题,就仿佛是参数列表正确一样:
int main(void) {
int x = 1, y = 2;
int res = add(x, y);
return 0;
}
int add(int x, int y) {
int sum = x + y;
return sum;
}这仅限于 C89 标准,从 C99 标准开始隐式函数声明也被废弃了,在严格的 C99 标准中,上述代码会得到如下报错:
| | In function 'main':
|3| error: implicit declaration of function 'add' [-Wimplicit-function-declaration]不过即便是 C89 标准,隐式函数声明也仅限于返回值为 int 类型的函数,例如下面的代码就会得到一个编译错误:
int main(void) {
int x = 1, y = 2;
int res = f(x, y);
return 0;
}
double f(int x, int y) {
int avg = (x + y) / 2.0;
return avg;
}但是请注意,在任何情况下你都不应该为利用这一特性为返回值为 int 类型的函数省略函数声明语句。
前文已经提到过,不推荐以任何形式利用空的参数列表和隐式 int 声明这两种分别是毫无意义和废弃的语法特性,而隐式函数声明却悄悄地触发了这两种语法特性。
对于缺失声明的函数,编译器不会对其参数进行检查,这意味着下面的的代码不会报告任何编译错误:
int main(void) {
int x = 1, y = 2, z = 3;
int res1 = add(x);
int res2 = add(x, y, z);
int res3 = add();
return 0;
}
int add(int x, int y) {
int sum = x + y;
return sum;
}相比起不负责任的程序员自己去利用这两种语法特性,这显然更加危险,因为没有一个函数声明能让你直接看到并发现它们被触发了。
因此,如果你的程序会在 C89 标准下运行,请一定要格外注意保证在调用前先声明函数,因为编译器会悄悄地产生一个隐式函数声明。这存在很大的潜在风险——上面的示例中都还算好的,在有些情况下,这一失误会导致你的程序存在崩溃的风险。至于具体的例子则可能不太适合初学者,就不在此赘述了。
函数的意义
函数有什么用?为什么要使用函数?这是编程初学者必须要理解的一个基础问题。
从理论上讲,即便你只用一个主函数来编写程序,不使用任何其它函数,也能实现一切你想实现的功能。然而实际上,当程序的规模大到一定程度时(甚至不用很大),这将带来灾难性的后果。
想象你在与人合作编写一个包含数十个源文件、总计上万行代码的软件系统,其中总计对数组排序数十次。如果你没有使用函数,那么你可能会把同一段代码复制粘贴数十次。假如有一天,你改变了排序的需求(例如把从小到大排序改成从大到小排序),或者你发现你不小心把排序的代码写错了,那么你就大祸临头了——你不得不在上万行代码中寻找你每一个对数组排序的地方,这非常浪费精力。甚至你不小心改漏了一个地方,你的程序里就埋下了一颗定时炸弹,因为你误以为你已经改好了这个问题。你将需要花费数倍的精力去寻找这唯一一处遗漏。
但是如果你将你的数组排序代码包装成一个函数,那么无论你在程序中对数组排序多少次,你都只需要调用这个函数即可:
sort(arr, n);一旦改变需求或发现错误,我们只需要修改一份代码就可以了,高效且安全。并且我们可以在全局搜索 sort 瞬间定位所有使用数组排序的位置。
因此我们可以粗略地归纳出使用函数的好处:
-
使代码易于修改和维护;
-
大幅减少不必要的代码冗余。
因此作为初学者你应当养成一个习惯:在写代码时,总是考虑这段代码是不是一个独立的子功能,是否可以包装成函数。
基于类似的原因,我们也提倡多使用结构体。例如学生的各种信息,如果不包装成结构体,那么当学生信息发生变化时(例如新增或削减信息条目、某条信息的类型或名称改变),你将会付出和不使用函数一样的代价。
事实上,这是一种被称为 模块化 (modularity) 的基本编程思想,指的是将复杂的程序划分为若干个子模块,分别设计实现每个子模块的功能和对外接口、输入和输出,然后将整个系统视为若干个模块的组织。这有利于(甚至可以说是必要的)设计和实现大型的软件系统。
函数类型
注:从本节开始往后包括函数类型、函数指针、可变参数的相关知识,这些相对而言不太算得上是“基础知识”了,建议读者根据自身情况酌情决定自己学习的时机。
基本概念
一些初学者可能并不知道,函数也是有类型的。这不是咬文嚼字,因为要想学好函数指针,必须先了解函数类型。此外,在 C++ 语言中对函数类型的运用比 C 语言更加精妙和复杂。
函数类型 (function types) 指的是专门用于描述函数的类型。它跟函数的名称及其各个参数的名称无关,只跟函数的返回值类型及其各个参数的类型有关。例如:
int f(int a, double b);该函数的类型标识符为 int (int, double) 。也就是说,所有返回值为 int 类型、有两个参数依次为 int 和 double 类型的函数的类型都是一样的。
与对象类型(也就是你通常见到的各种基本类型、指针类型、结构体、数组等等)不同,函数类型没有大小的概念,你不能用 sizeof 运算符来获取一个函数类型的大小,这通常会得到一个编译错误。
函数指针
我们也可以定义指向函数的指针——就像指向 int 类型的指针或指向 double 类型的指针一样,我们可以定义一个指向特定函数类型的指针,例如一个指向 int (int, double) 类型的函数指针 ,其类型标识符为 int (*)(int, double) :
int (* p)(int, double);如果有需要的话,你也可以标明参数的名称,虽然这没有实际作用,就像函数声明中的参数名称一样没有作用:
int (* p)(int a, double b);但是要注意不能写成:
int * p(int, double);根据运算符优先级,这将声明一个返回值为 int * 类型的、名为 p 的函数,而不是一个指向 int (int, double) 类型的函数指针。
与普通指针不同,函数指针指向代码,而不是数据。通常,函数指针中存储的值为可执行代码的开头的地址。另外,我们也不能用函数指针来动态分配内存。
我们看下面的代码示例:
#include <stdio.h>
int f(int a, double b) {
return a + (int)b;
}
int g(int a, double b) {
return (int)(a * b);
}
int main(void) {
int (* p)(int, double) = &f;
int x, y;
x = p(1, 2.5);
p = &g;
y = (*p)(2, 2.5);
printf("%d %d\n", x, y);
return 0;
}上述代码的输出结果如下:
3 5给函数指针赋值的语法并不复杂,和普通的指针基本一致。但是在对函数指针解引用时,根据语法规定,上面第 和 行使用的两种语法是等价的。换句话说,我们没有必要使用解引用运算符,直接把函数指针视为函数名去使用就可以了,因为函数名本身也具有函数地址的信息。
轻松一下,你甚至可以写成下面这样:
y = (**********p)(2, 2.5);这仍然是正确的,不过这没什么意义。
函数指针的类型必须与其指向的函数类型相同,即函数的返回值类型及其各个参数的类型必须完全匹配,例如:
int f(int a, double b) {
return a + (int)b;
}
int f1(double a, int b) {
return (int)a + b;
}
int f2(int a, int b) {
return a + b;
}
double f3(int a, double b) {
return a + b;
}
int main(void) {
int (* p)(int, double) = &f;
p = &f1;
p = &f2;
p = &f3;
return 0;
}上述代码会得到如下编译错误:
| | In function 'main':
|15| error: assignment from incompatible pointer type
|16| error: assignment from incompatible pointer type
|17| error: assignment from incompatible pointer type我们也可以声明一个元素为函数指针的数组,例如:
int add(int a, int b) {
return a + b;
}
int sub(int a, int b) {
return a - b;
}
int mul(int a, int b) {
return a * b;
}
int div(int a, int b) {
return a / b;
}
int main(void) {
int (* arr_p[4])(int, int) = {add, sub, mul};
int x = arr_p[0](1, 2);
int y = (* arr_p[1])(3, 0);
arr_p[3] = div;
return 0;
}函数指针的运用
函数指针是非常有用的,我们经常会将其作为函数参数或返回值来使用。
函数指针作为函数参数
假设你编写了一个用来给数组排序的函数,并且现在你有多种不同的排序需求,例如,可能有时想从小到大排序,有时又想从大到小排序,有时还想根据元素的平方值从小到大排序,等等。
如果没有函数指针的话,你就不得不为每一种需求编写一个排序函数,这将导致大量的代码冗余。但是现在我们可以很轻松地解决这一问题:
#include <stdio.h>
// 选择排序法
void select_sort(int a[], int n, int (* cmp)(int, int)) {
int i, j;
int m;
int t;
for (i = 0; i < n; i ++) {
m = i;
for (j = i + 1; j < n; j ++) {
if (cmp(a[j], a[m])) {
m = j;
}
}
t = a[m];
a[m] = a[i];
a[i] = t;
}
}
// 输出
void output(int a[], int n) {
int i;
for (i = 0; i < n; i ++) {
printf("%d", a[i]);
printf(i == n - 1 ? "\n" : " ");
}
}
// compare
int less(int a, int b) {
return (a < b);
}
int greater(int a, int b) {
return (a > b);
}
// 主函数
int main(void) {
int a[] = {1, 0, 3, 2, 6, 4, 5};
int n = 7;
select_sort(a, n, less);
output(a, n);
select_sort(a, n, greater);
output(a, n);
return 0;
}上述代码的运行结果如下:
0 1 2 3 4 5 6
6 5 4 3 2 1 0类似于数组名作为函数参数时的情况,我们在语法上也可以用函数名来代替函数指针,但二者实质上是等价的,函数名将被视为函数指针:
void select_sort(int a[], int n, int cmp(int, int));函数指针作为函数返回值
接下来,我们假设你定义了一个函数,它通过一些计算来决定我们后续的程序会使用哪个函数,那么在一些情况下让该函数返回一个函数指针是非常合适的。
一个小小的麻烦是,使用函数指针作为函数的返回值的语法非常的古怪,例如:
void (* f(short, char))(int, int);上述代码声明了一个返回值类型为 void (*)(int, int) 、两个参数的类型为 short 和 char 的函数。这看起来很古怪,但是你可以和一个指向 void (int, int) 类型的函数指针对比来看:
void (* p)(int, int);其实就是把 替换成了 f(short, char) ,这样看就比较容易理解和记忆了。
下面给出了一个没什么实际意义的演示用例:
#include <stdio.h>
int less(int a, int b) {
return (a < b);
}
int greater(int a, int b) {
return (a > b);
}
int (* f(int a, double b))(int, int) {
if (a < b) {
return &less; // or return less;
} else {
return greater; // or return &greater;
}
}
int main(void) {
int (* p)(int, int) = f(0, 0.5);
printf("%d\n", p(1, 2));
p = f(1, 0.5);
printf("%d\n", p(1, 2));
return 0;
}上述代码的输出结果如下:
1
0由于使用函数指针作为函数的返回值的语法的可读性实在太差,尤其是当实际情况比较复杂时,这语法简直堪称反人类,所以我们通常都不会直接这么写,而是利用 typedef 来简化代码。这部分属于进阶内容,读者可以自行查阅相关资料。
可变参数
基本概念
C 语言自 C89 起就提供了 可变参数 (variable arguments) 的机制。借助可变参数,你可以在调用某个函数时每次传入数量和类型不同的参数,并且能够直接获取和处理它们。调用时传入的这样一组不定参数被称为一个 可变参数列表 (variable argument list) 。
可变参数机制是非常有用的,例如你所熟悉的 scanf 和 printf 就可以利用可变参数来实现。尽管其底层实现并未直接调用我们下面介绍的高层语法接口,但是本质上是相同的。有了可变参数,你就可以实现自己的 printf ,以及其它有类似需求的特殊函数了。
语法规则
声明可变参数的语法为 ... ,即三个半角句号。可变参数只能出现在函数参数列表的末尾,且函数不能只有可变参数,例如:
void f1(int, ...); // ok
void f2(char *, double, ...); // ok
void f3(..., int[], int); // illegal
void f4(int, ..., double); // illegal
void f5(...); // illegal以 f1 为例,下列调用都是合法的:
void f1(int, ...);
int x = 0;
char * s = "str";
f1(1);
f1(6, 1, 2, 3);
f1(17, x, 2.5, 'c');
f1(2, &x, x + 4, s);获取和处理可变参数则需要引用头文件 stdarg.h ,该头文件定义了一个类型和四个宏来处理可变参数。这里面的规则比较冗杂,我们借助一段完整的示例代码来帮助理解:
#include <stdio.h>
#include <stdarg.h>
void f(int arr[], int n, ...) {
va_list ap;
va_start(ap, n);
for (int i = 0; i < n; i ++) {
arr[i] = va_arg(ap, int);
}
va_end(ap);
}
int main(void) {
int arr[6] = {0};
int n = 6;
f(arr, n, 3, 1, 2, 5, 4, 6);
return 0;
}类型 va_list 用于实现可变参数列表,保存了可变参数宏所需的所有信息。如果需要访问可变参数,那么被调用的函数需要声明一个类型为 va_list 的变量。该变量的名称习惯上缩写为 ap 。
宏 va_start(ap, paramN) 用于初始化可变参数列表 ap ,并将函数参数 paramN 之后的参数视为可变参数提取到 ap 中。
宏 va_arg(ap, type) 用于解析已初始化的可变参数列表 ap ,每次调用会从 ap 中以 type 类型获取当前参数,并将 ap 推进至下一个参数。
宏 va_copy(ap_dst, ap_src) 将 ap_src 及其当前状态复制到 ap_dst 。该宏会先初始化 ap_dst ,因而先调用 va_start(ap_dst) 再调用 va_copy 是错误的。
宏 va_end(ap) 需要为每个被使用过的可变参数列表而调用,它会执行一些必要的底层操作,以确保函数能正常返回。
一些需要注意的语法规则包括:
在调用 va_arg 之前,必须先调用 va_start 或 va_copy 对 ap 进行初始化,且还未调用过 va_end 终结。
在调用 va_arg 时必须确保 type 指示了正确的、与 ap 当前所指的参数对应的类型,错误的类型会触发未定义行为(除非是相匹配的 signed 和 unsigned 类型且不会发生有符号整数溢出,或是 void * 和 char * 类型)。
va_arg 无法判断可变参数是否已经全部读完,也不具备类似字符串末尾的 '\0' 的标识,因此函数代码必须有另外的办法(例如传入一个额外的参数来记录可变参数的个数)来判断何时读完,避免读取越界。
va_arg 无法判断每个可变参数的类型,因此如果传入了多种类型的参数,函数代码必须有另外的办法来判断参数的类型。例如 scanf 和 printf 会根据格式化字符串来解析类型;也可以根据实际需求在文档和注释中注明以避免误用,例如规定前两个可变参数为 int 而后续参数皆为 double ,等等。
va_start , va_copy 与 va_end 之间的关系就好像 malloc , alloc 与 free 之间的关系一样,每一个可变参数列表 ap 的初始化和终结都需要一一对应。根据 C 语言标准,在函数返回时缺少 va_end 将触发未定义行为,多次调用 va_end (除非先调用 va_start 或 va_copy 重新初始化)也将触发未定义行为。
语法运用
另外,存在一些谣言声称 va_start 的 paramN 参数表示函数调用时传入的可变参数的个数,这是完全错误的。尽管在实际使用时,我们确实需要传入一个参数来记录可变参数的个数,因为 C 语法不提供能直接获取此信息的语法,但这和 paramN 参数是两回事。例如下面的代码就是合法的,直接击破谣言:
void f(int n, double x, ...) {
va_list ap;
va_start(ap, x);
for (int i = 0; i < n; i ++) {
printf("%d", va_arg(ap, int));
}
va_end(ap);
}
int main(void) {
f(4, 23.33, 11, 22, 3, 44);
return 0;
}其它
可变参数机制的实现依赖于底层的运行环境和具体的运行库,在不同的环境下 stdarg.h 内的具体实现可能会不同,例如 GNU C 在 x86 下将 valist 定义为 char * 类型,但并非总是如此。
实际上 C 语言在语法层面只提供了可变参数的声明语法 ... ,而其解析则依赖于标准库的实现,所以你当然可以自己写代码实现可变参数列表的解析。但是注意,简单的实现可能影响程序的可移植性。除非确有必要,否则调用 stdarg.h 提供的通用接口是更好的选择。
文章更新记录
| 更新时间 | 更新内容 |
|---|---|
| 2020.3.17 | 为章节【使用指针作为函数参数】追加内容 |
| 2020.3.17 | 追加章节【可变参数】 |