
C Programming Language
Expertise #05: Memory Layout and Rules
# Basic Tutorial, # Programming Language, # C Programming LanguageLast Updated: 2020-07-01
前置知识
在阅读本文档前,请确保你已经掌握动态内存分配的基础知识,详见 Basics #08: Dynamic Memory Allocation 。
请注意:本文是面向进阶读者的,在阅读本文档前,请确保你已经具备了较为完整的 C 语言基础。
前言
要想深入了解 C 语言,先掌握其内存模型和布局是必不可少的步骤。本文对 C 语言的内存相关知识进行了详细的介绍。
内存布局
整体模型
C 语言的内存布局总体上可以分为代码段、(静态)数据段、堆区和栈区四大区域,如下图所示。
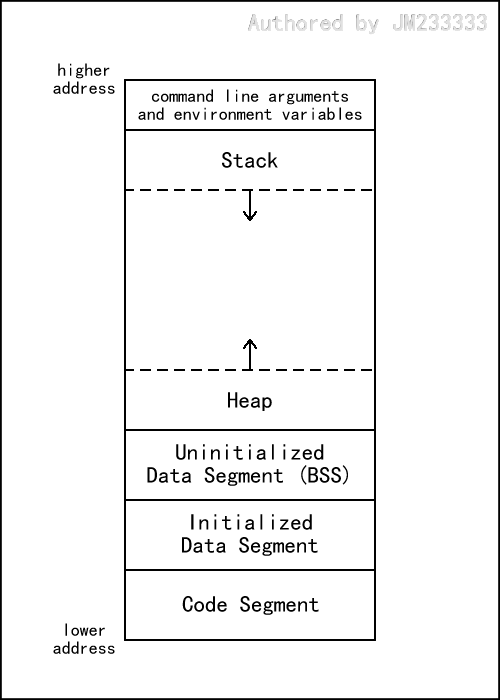
在不同的系统环境下,各个内存区域的相对位置可能不同(例如代码段和数据段可能在靠近高地址的一侧),但是堆和栈通常都会像图中那样在一起(谁在高低地址位是不一定的),在共享空间内沿着相反的方向增长,二者的头部相遇则意味着内存耗尽,而代码段和数据段则通常位于堆栈区域的“外围”。
代码段
代码段 (Code Segment) 用于存储源程序编译后产生的二进制机器码,即可执行机器指令,有时也称为 文本段 (Text Segment) ,是目标文件或内存中程序的一部分。
代码段通常是可共享的,因此对于频繁执行的程序(例如文本编辑器、编译器和 shell 等),仅一个副本需要存储在内存中。
代码段通常是只读的,以防止程序中触发的非法内存访问修改了代码段中的指令,导致严重后果。
数据段
数据段 (Data Segment) 用于存储全局变量、静态变量和字符串常量,该区域又可细分为初始化数据段和未初始化数据段。
初始化数据段 (Initialized Data Segment) 用于存储数据段中的以下数据:
-
无 const 修饰,且被初始化为 非零值 的所有全局变量和静态变量;
-
有 const 修饰,且被显式初始化为任意值的所有全局变量和静态变量;
-
所有字符串常量。
初始化数据的又分为 初始化只读区域 (initialized read-only area) 和 初始化可读写区域 (initialized read-write area) 。顾名思义,不可修改的数据(包括字符串常量)都存储在只读区域,而其它可修改的数据则存储在可读写区域。例如:
int a = 1; // stored in initialized read-write area
const int b = 2; // stored in initialized read-only area
int c = 0; // NOT stored in initialized data segment
const int d = 0; // stored in initialized read-only area
const int e; // NOT stored in initialized data segment
char[] s = "abc"; // stored in initialized read-write area
const char[] t = "def"; // stored in initialized read-only area
char * p = "foo"; // discussed later
int main(void) {
static int x = 1; // stored in initialized read-write area
static const int y = 2; // stored in initialized read-only area
const int z = 3; // NOT stored in initialized data segment
return 0;
}用字符串初始化的字符指针则需要特别注意。在上例中,指针 p 将存储在可读写区域,而字符串常量 "foo" 则存储在只读区域。但是上例中的 "abc" 和 "def" 都不会作为字符串常量被存储,因为 s 和 t 被定义为 char 数组而非 char 指针。
两个容易记错的情况:
-
被初始化为零值但是有 const 修饰的全局或静态变量。此类变量会被存储在初始化数据段的只读区域,例如上例中的
d。 -
未被显式初始化但是有 const 修饰的全局或静态变量。此类变量会被存储在未初始化数据段,例如上例中的
e。
未初始化数据段 (Uninitialized Data Segment) 用于存储数据段中的以下数据:
-
无 const 修饰,且被程序显式初始化为 零值 的全局变量和静态变量;
-
未被程序显式初始化的全局变量和静态变量,无论是否有 const 修饰。
在程序开始执行之前,该区域中的数据会被自动地初始化为零值。该区域有时也被称为 BSS 段 (Block Started by Symbol, BSS) 。
下面是一个验证上述内容正确性的简单程序,假设在程序的运行环境中 int 类型的长度为 位,且程序运行在 位环境:
#include <stdio.h>
int a = 1;
int b = 0;
const int c = 2;
int d = 3;
const int e = 0;
int f = 0;
const int g = 4;
int h = 5;
int i = 0;
int j;
const int k;
int l;
int main(void) {
printf("%u %u %u\n", &a, &d, &h); // initialized read-write area
printf("%u %u %u\n", &c, &e, &g); // initialized read-only area
printf("%u %u %u\n", &b, &f, &i); // uninitialized data segment
printf("%u %u %u\n", &j, &k, &l); // uninitialized data segment
return 0;
}上述代码在我本机上的某次运行结果如下:
4222984 4222980 4222976
4227128 4227124 4227120
4235280 4235276 4235272
4237856 4237860 4237864根据变量地址的连贯性,我们可以很容易地判断出各个变量的存储区域都是符合规则的。
堆区和栈区
栈区 (Stack) 用于存储所有的局部变量,包括函数参数以及在函数体内定义的所有非静态变量。 堆区 (Heap) 用于进行动态分配内存,例如由 malloc 或 calloc 等函数分配的存储空间都位于堆区。
堆栈区域所存储的都是在运行时刻才能决定的内存分配。对于栈区,局部变量的产生受函数调用和分支逻辑决定;对于堆区,动态分配内存完全取决于运行时刻的各种程序状态。以下面的代码为例:
void f(int x) {
int a, b;
// ...
}
void g(int x, int y) {
int a, b, c;
// ...
}
int main(void) {
int n;
scanf("%d", &n);
if (n > 0) {
f(1);
} else {
g(1, -1);
}
return 0;
}如果输入满足 ,则栈区头部新使用的内存包括三个整型变量,反之则包括五个整型变量,只有在程序的运行时刻才可能知道内存分配的具体大小。而代码段和数据段的具体大小都可以在编译时刻确定。
堆区和栈区通常沿着相反的方向增长,并且“起点”位于堆栈区的相反两端,正如前文的内存布局示意图中所示。
栈区的存储方式与数据结构中的栈相同。而堆区的存储方式则并非像数据结构中的堆那样,二者完全无关。
内存对齐与填充
前言
对初学者来说,内存对齐是一个很有趣的现象。依据内存对齐进行空间优化是许多底层代码所关注的问题,是深入学习 C/C++ 语言所必须了解的。
为了引入这个问题,我们先看如下代码:
struct block {
int x;
char ch;
};
printf("%d", sizeof(struct block));你觉得应该是多少?答案并不等于 sizeof(int) + sizeof(char) ,输出的结果不是 5 ,而是令人惊奇的 8 。
再看另一个示例:
struct block1 {
int x;
short a;
short b;
};
struct block2 {
short a;
int x;
short b;
};
printf("%d %d", sizeof(struct block1), sizeof(struct block2));输出的结果是 8 12 ,同样的成员变量,两个结构体的大小竟然并不相同。
这些看似神奇的现象,其背后的原理正是 C/C++ 语言的内存对齐机制。
基本概念
简单来说, 内存对齐 (memory alignment) 是 C/C++ 语言为了提高程序的运行效率、以及为了与下层的体系结构和处理器相兼容,而设计的一种机制,该机制规定了数据在复合数据结构中的排布规则。有时也称为 数据结构对齐 (data structure alignment) ,实际上指的是同一个东西。
与之共存的是,在对 struct 这样的复合类型内部的成员进行内存对齐的时候,会产生一些冗余区域,编译器会使用一些匿名内存填满这些区域,称为 内存填充 (memory padding) 。
为什么要有内存对齐?往深了挖的话,这是一个非常复杂的问题。简单来说,在多种原因的推动下,计算机处理器选择尽量以内存对齐的方式处理数据,这样更加高效,并且能避免很多不必要的麻烦;而作为最接近底层的高级语言之一,在 C 语言中直接遵循内存对齐的规则也就不奇怪了。
注:如果读者对内存对齐背后的理由感兴趣,可以查阅本节末尾附的链接。这部分内容已经超出了编程语言的范畴,会涉及大量的计算机体系结构的相关知识。
基本类型的内存对齐
在 位 x86 环境下,根据 C 语言标准,基本数据类型的内存长度与内存对齐长度如下表所示,单位为字节数:
| 类型 | 长度 | 对齐长度 |
|---|---|---|
char | 1 | 1 |
short | 2 | 2 |
int | 4 | 4 |
long | 4 | 4 |
float | 4 | 4 |
double | 8 | 8 or 4 |
long long | 8 | 4 |
T * | 4 | 4 |
数组类型 T [] 的对齐长度与类型 T 相同。
在默认情况下,对于存储在相同内存区域的若干个变量(例如一组在 main 函数内定义的局部变量),编译器会在遵循内存对齐规则的前提下,自由地调整各个变量的相对位置,以尽可能地节省空间消耗。
我们将利用几组示例来辅助理解这一点,每组示例包括代码、运行结果和相对位置的图示(图中每个方块表示一个字节)。为了节省文章页面,我们会将多个不同类型的变量的声明语句挤压到一行内,但这不是一个好的代码习惯。注意,在不同运行环境和不同编译参数下,这些变量在内存中的具体地址和相对位置都可能会不同。
示例 :
int main(void) {
int a; int b; int c;
printf("%x %x %x\n", &a, &b, &c);
return 0;
}61fef4 61fef8 61fefcf4 f8 fc
+---------------+---------------+---------------+
| a | b | c |
+---------------+---------------+---------------+示例 :
int main(void) {
int a; char b; int c;
printf("%x %x %x\n", &a, &b, &c);
return 0;
}61fef8 61fef7 61fefcf4 f7 f8 fc
+---+---+---+---+---------------+---------------+
| / | / | / | b | a | c |
+---+---+---+---+---------------+---------------+示例 :
int main(void) {
int a; char b; short c; char d;
printf("%x %x %x %x\n", &a, &b, &c, &d);
return 0;
}61fefc 61fef8 61fefa 61fef9f4 f8 f9 fa fc
+---+---+---+---+---+---+-------+---------------+
| / | / | / | / | b | d | c | a |
+---+---+---+---+---+---+-------+---------------+示例 :
int main(void) {
char a; int b; char c; short d; char e; short f;
printf("%x %x %x %x %x %x\n", &a, &b, &c, &d, &e, &f);
return 0;
}61fef5 61fefc 61fef6 61fef8 61fef7 61fefaf4 f5 f6 f7 f8 fa fc
+---+---+---+---+-------+-------+---------------+
| / | a | c | e | d | f | b |
+---+---+---+---+-------+-------+---------------+可以看到, 在我的运行环境下, 对于长度相同的变量,编译器只是简单地将其顺序排布;否则,编译器会尽量把几个长度相同的变量靠在一起,以减少由内存对齐引起的空间浪费。
当数组变量加入时,排布的情况会更加复杂。遵循对齐原则时,变量之间有时会产生空余的内存区域。受篇幅所限,这里就只展示几个简单的例子,复杂的组合读者可自行尝试。
示例 :
int main(void) {
char a[2]; char b[4]; short c[3];
printf("%x %x %x\n", &a, &b, &c);
return 0;
}61fef4 61fef6 61fefaf4 f6 fa
+---+---+---+---+---+---+-------+-------+-------+
| a . | b . . . | c . . |
+---+---+---+---+-------+-------+-------+-------+示例 :
int main(void) {
char a[3]; char b[3]; short c[2];
printf("%x %x %x\n", &a, &b, &c);
return 0;
}61fef6 61fef9 61fefcf6 f9 fc
+---+---+---+---+---+---+-------+-------+
| a . . | b . . | c . |
+---+---+-------+---+---+-------+-------+示例 :
int main(void) {
short a[2]; char b[5]; short c[3];
printf("%x %x %x\n", &a, &b, &c);
return 0;
}61fef0 61fef5 61fefaf0 f4 f5 fa
+-------+-------+---+---+---+---+---+---+-------+-------+-------+
| a . | / | b . . . . | c . . |
+-------+-------+---+---+---+---+---+---+-------+-------+-------+需要注意的是,在不同的运行环境和编译参数下,基本类型的对齐长度可能会不同,这也将进一步影响到结构体和联合体类型的对齐长度。但是标准规定的对齐规则是不会随环境而变的,无论对齐长度是多少。
结构体类型的内存对齐与填充
根据 C 语言标准,结构体类型的内存对齐遵循如下规则:
-
在默认情况下,结构体类型的对齐长度为结构体内所有成员的对齐长度的 最小公倍数 ;这导致结构体类型的长度为 的最小整数倍数 ,使其内存大小足够装下所有成员;
-
在结构体内部,结构体内的每个成员都要按照该成员类型的对齐长度来对齐;形式化地讲,设成员类型的对齐长度为 ,那么该成员的偏移地址一定是 的整数倍。
-
结构体用若干段匿名内存填充由内存对齐所产生的冗余区域,称为 内存填充 (memory padding) ;结构体的首部不能有内存填充,而成员之间及末尾都可能有;
上述规则本身不受运行环境和编译参数的影响,但基本类型的对齐长度会受到影响,进而影响到结构体的对齐长度。
我们将利用几组示例来辅助理解上述规则,每组示例包括代码、运行结果和相对位置的图示。这些示例囊括了本节最初的两组示例。
示例 :
struct block {
int a; char b;
} t;
printf("%-2d %x %x\n", sizeof(t), &t.a, &t.b);8 61fef8 61fefcf8 fc
+---------------+---+---+---+---+
| a | b | / | / | / |
+---------------+---+---+---+---+示例 :
struct block {
int a; char b; short c;
} t;
printf("%-2d %x %x %x\n", sizeof(t), &t.a, &t.b, &t.c);8 61fef8 61fefc 61fefef8 fc fe
+---------------+---+---+-------+
| a | b | / | c |
+---------------+---+---+-------+示例 :
struct block {
int a; short b; short c;
} t;
printf("%-2d %x %x %x\n", sizeof(t), &t.a, &t.b, &t.c);8 61fef8 61fefc 61fefef8 fc fe
+---------------+-------+-------+
| a | b | c |
+---------------+-------+-------+示例 :
struct block {
short a; int b; short c;
} t;
printf("%-2d %x %x %x\n", sizeof(t), &t.a, &t.b, &t.c);12 61fef4 61fef8 61fefcf4 f8 fc
+-------+---+---+---------------+-------+---+---+
| a | / | / | b | c | / | / |
+-------+---+---+---------------+-------+---+---+示例 :
struct block {
short a; short b; short c;
} t;
printf("%-2d %x %x %x\n", sizeof(t), &t.a, &t.b, &t.c);6 61fefa 61fefc 61fefefa fc fe
+-------+-------+-------+
| a | b | c |
+-------+-------+-------+示例 :
struct block {
short a; char b; short c;
char d; char e; short f;
} t;
printf("%-2d %x %x %x %x %x %x\n",
sizeof(t), &t.a, &t.b, &t.c, &t.d, &t.e, &t.f);10 61fef6 61fef8 61fefa 61fefc 61fefd 61fefef6 f8 fa fc fd fe
+-------+---+---+-------+---+---+-------+
| a | b | / | c | d | e | f |
+-------+---+---+-------+---+---+-------+可以看到,即便是完全相同的成员类型的组合,不同的顺序也会导致结构体的总长度相差甚远。因此,在有必要的情况下(例如需要存储大量的结构体),我们需要合理地排布成员变量以避免空间浪费。
需要注意的是,当修改结构体及联合体的数据时(例如为其成员赋值),其内部的匿名填充内存中的数据状态属于未指定行为,因此下面两种定义事实上是不等价的,尽管人为设置但不使用的 padding 数组看起来只是占据了匿名填充内存的位置:
struct block {
int a;
char b;
int c;
}
struct block {
int a;
char b;
char padding[3];
int c;
}事实上, C 语言也支持手动指定结构体的对齐长度。预处理指令 #pragma pack(n) 可以指示编译器按对齐长度 打包结构体成员,而 #pragma pack() 会恢复当前环境中默认的对齐长度。
类似地,我们还是利用示例来理解其作用:
int main(void) {
#pragma pack(1)
struct block1 {
char a; int b; char c;
} t1;
#pragma pack(2)
struct block2 {
char a; int b; char c;
} t2;
#pragma pack()
struct block {
char a; int b; char c;
} t;
printf("%-2d %x %x %x\n", sizeof(t1), &t1.a, &t1.b, &t1.c);
printf("%-2d %x %x %x\n", sizeof(t2), &t2.a, &t2.b, &t2.c);
printf("%-2d %x %x %x\n", sizeof(t), &t.a, &t.b, &t.c);
return 0;
}6 61fee6 61fee7 61feeb
8 61feec 61feee 61fef2
12 61fef4 61fef8 61fefce6 e7 eb
+---+---------------+---+
| a | b | c |
+---+---------------+---+
ec ee f2
+---+---+---------------+---+---+
| a | / | b | c | / |
+---+---+---------------+---+---+
f4 f8 fc
+---+---+---+---+---------------+---+---+---+---+
| a | / | / | / | b | c | / | / | / |
+---+---+---+---+---------------+---+---+---+---+需要注意的是,尽管 #pragma pack 确实极力压缩了空间,但是它也会降低程序的执行效率,以及引入一些其它的负面结果——内存对齐会浪费空间,但这么做显然是有必要的。具体原因涉及计算机体系结构的相关知识,这里就不再深入探讨了。
因此,除非确实有必要,以及你很清楚自己在做什么,否则不要滥用这个指令,毕竟手动调整成员的排列顺序通常足以解决问题。
延伸阅读
https://medium.com/dev-genius/c-programming-hacks-01-memory-efficient-struct-design-8e7252c2b986
https://developer.ibm.com/technologies/systems/articles/pa-dalign/
https://stackoverflow.com/questions/381244/purpose-of-memory-alignment
文章更新记录
| 更新时间 | 更新内容 |
|---|---|
| 2020.3.18 | 追加章节【内存对齐与填充】 |